
在拉斯维加斯举行的 Google Cloud Next 2024 大会上,Google 宣布将向所有用户全面开放 Gemini 1.5 Pro。备受期待的 Gemini1.5 Pro 终于进入了公开预览阶段,并提供了100 万个上下文窗口,用户无需再注册等待即可使用 Gemini 1.5 Pro。
我试着用新的谷歌账户访问 Gemini 1.5 Pro 模型,结果发现该模型随时可用,无需等待。而且这一切都是免费的。
但这并不意味着您可以在 Gemini 门户网站上开始使用 Gemini 1.5 Pro 模型。目前,您必须前往aistudio.google.com(访问)才能访问该模型。经过几个月的公开预览后,该模型将在 Gemini 门户网站上提供。您可能需要订阅 Gemini Advanced 才能使用该模型。
请记住,Gemini 1.5 Pro 模型是基于 MoE 架构的中级模型,但它能轻松击败最大的 Gemini 1.0 Ultra 模型。在与 GPT-4 模型的比较中,Gemini 1.5 Pro 在多项测试中表现出了不凡的能力。当 Gemini 1.5 Pro 在 Gemini 门户网站上亮相时,预计它的性能将优于 GPT-4 和 Claude 3 的 Opus 型号。
除此之外,Gemini 1.5 Pro 现在还能处理音频文件。您可以上传会议或视频的音频文件,而模型可以收听上传的文件,无需手动生成文字记录。这对那些希望从音频会议或讨论中快速找到结构化信息的人来说大有裨益。
Gemini 1.5 Pro已经可以处理视频和图像,现在还支持音频文件,这使它成为一个强大的多模态模型,上下文长度可达 100 万个标记。我们测试了 Gemini 1.5 Pro 模型的音频处理能力。具体操作如下:
- 在浏览器中访问 aistudio.google.com。
- 然后,确保在下拉菜单中选择 “Gemini 1.5 Pro” 模型。
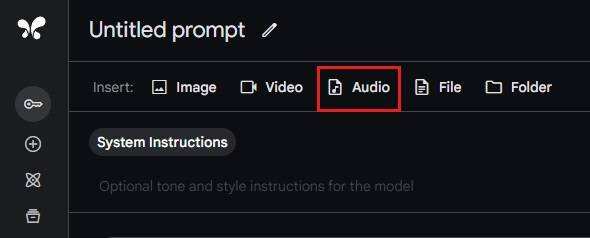
- 然后,点击顶行的 “Audio” 菜单,上传音频文件。它支持这些音频文件格式: FLAC、MIDI、MP3、M4A、OPUS、OGG、OGA、WAV 和 MID。
- 它将处理音频文件并消耗 tokens。
- 现在,开始提问吧,Gemini 1.5 Pro 会从音频中找到信息并作出相应的回应。
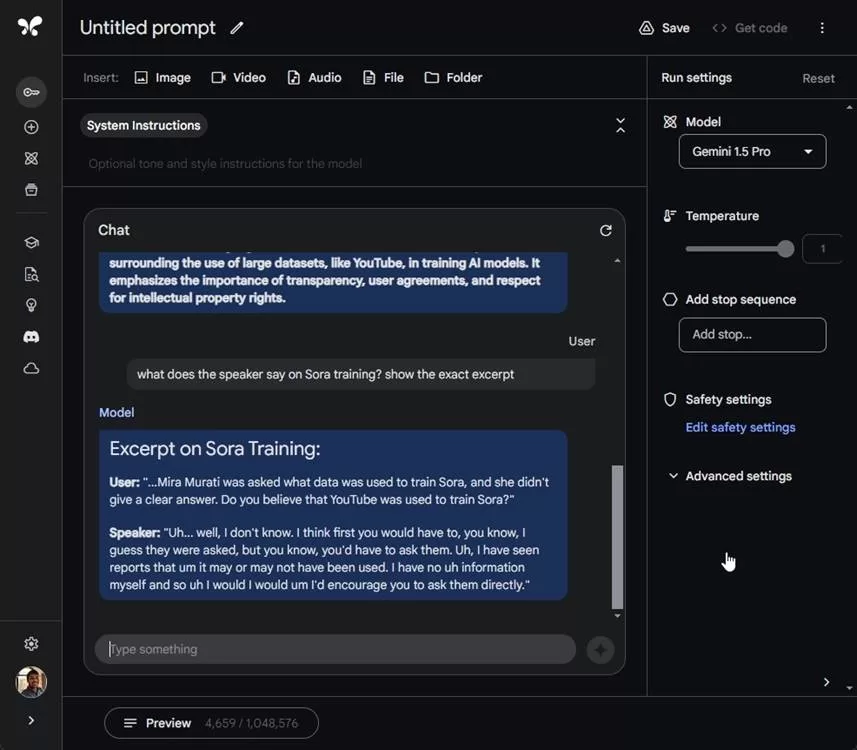
- 最棒的是,它能以结构化的格式生成脚本文字,并标注不同的发言人。而且完全不会产生幻觉。
![]()
这就是在 Gemini 1.5 Pro 上上传和处理音频文件的方法。这确实是谷歌 DeepMind 团队的一个强大模型,我很高兴它现在可以免费向公众开放。快来试试吧,并在下面的评论区告诉我们你的想法。
免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。












暂无评论内容