

多模态检索增强生成(RAG)是人工智能领域的一项变革性创新,它使系统能够处理和整合文本、图像、音频和视频等多种数据类型。这种能力对于应对主要由多模态格式组成的非结构化企业数据的挑战至关重要。通过利用多模态输入,RAG 增强了对上下文的理解,提高了准确性,并扩大了人工智能在医疗保健、客户支持和教育等行业的适用性。
Docling 是 IBM 开发的开源工具包,用于简化生成式人工智能应用的文档处理。我们将利用 Docling 构建多模态 RAG 能力。它能将 PDF、DOCX 和图片等多种格式转换为 JSON 和 Markdown 等结构化输出,从而实现与 LangChain 和 LlamaIndex 等人工智能框架的无缝集成。通过促进非结构化数据的提取和支持高级布局分析,Docling 可使复杂的企业数据具有机器可读性并可用于人工智能驱动的洞察力,从而增强多模态检索增强生成(RAG)的能力。
学习目标
- 探索 Docling– 了解它如何从非结构化文件中提取多模态信息。
- Docling 管道和人工智能模型– 研究其架构和关键人工智能组件。
- 独特功能– 突出 Docling 的与众不同之处。
- 构建多模态 RAG 系统– 使用 Docling 实现数据提取和检索系统。
- 端到端流程– 从 PDF 中提取数据、生成图像描述,以及使用矢量数据库和 Phi 4 进行查询。
用于非结构化数据的Docling
Docling 是由IBM 开发的开源文档处理工具包,旨在将 PDF、DOCX 和图像等非结构化文件转换为 JSON 和 Markdown 等结构化格式。它由先进的人工智能模型(如用于布局分析的 DocLayNet 和用于表格识别的 TableFormer)提供支持,能够在保留文档结构的同时准确提取文本、表格和图像。通过与 LangChain 和 LlamaIndex 等生成式人工智能框架的无缝集成,Docling 支持检索增强生成(RAG)和问题解答系统等应用。其轻量级架构可在标准硬件上实现高效性能,使其成为寻求数据隐私控制的企业在基于 SaaS 的解决方案之外的另一种经济高效的选择。
Docling管道
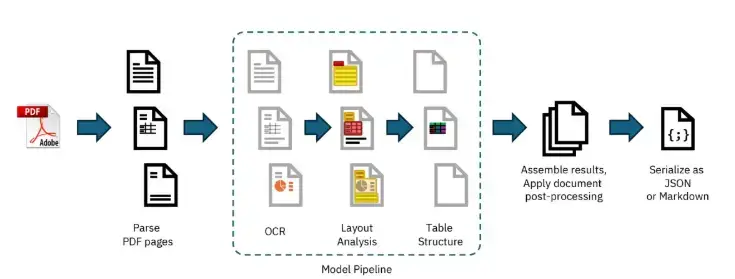
Docling 的默认处理管道。模型管道的内部部分可轻松定制和扩展。图片来源
Docling 实现了对每个给定文档按顺序执行的线性操作流水线(如上图所示)。每个文档首先由 PDF 后端进行解析,检索由字符串内容及其在页面上的坐标组成的编程文本标记,同时渲染每个页面的位图图像,以支持下游操作。然后,标准模型流水线在文档的每一页上独立应用一系列人工智能模型,以提取特征和内容,如布局和表格结构。最后,所有页面的结果都会汇总并通过后处理阶段,后处理阶段会增强元数据、检测文档语言、推断阅读顺序,并最终生成一个类型化的文档对象,该对象可序列化为 JSON 或 Markdown。
Docling背后的关键人工智能模型
传统上,开发人员依赖光学字符识别(OCR)将文档转换为数字格式。然而,由于需要大量的计算能力,这种技术可能会很慢,而且容易出错。Docling 尽可能避免使用 OCR,而是使用经过专门训练的计算机视觉模型来识别和分类页面的视觉组件。
Docling 基于 IBM 研究人员开发的两个模型。
版面分析模型
布局分析模型具有对象检测器的功能,可预测给定页面图像中各种元素的边界框和类别。该模型的设计基于 RT-DETR,并使用 DocLayNet(我们著名的用于文档布局分析的人类注释数据集)和其他专有数据集进行了重新训练。DocLayNet 是一个由人工标注的文档布局分割数据集,包含来自各种文档来源的 80863 个页面。
该模型利用对象检测技术来检查从机器手册到年度报告等各种文档的布局。然后对文本块、图像、表格、标题等元素进行识别和分类。Docling 管道以 72 dpi 的分辨率处理页面图像,使其能够由单个 CPU 处理。
表格格式模型
TableFormer 模型最初于 2022 年推出,随后使用自定义标记结构语言进行了增强,它是一种视觉转换器模型,设计用于恢复表格结构。它可以根据输入图像预测表格中行和列的逻辑组织,识别哪些单元格属于列头、行头或表格主体。与以往的方法不同,TableFormer 能有效处理各种复杂的表格,包括部分或没有边框、空单元格、缺行或缺列、单元格跨度、列标题和行标题中的层次结构,以及缩进或对齐方式的不一致。
Docling的一些主要功能
以下是其特点:
- 支持多种格式:Docling 可以解析多种文档格式,包括 PDF、DOCX、PPTX、HTML、图片等。它可将内容导出为 JSON 和 Markdown 等结构化格式,以便无缝集成到人工智能工作流中。
- 高级 PDF 处理:它包含复杂的功能,如布局分析、阅读顺序检测、表格结构识别和扫描文档的 OCR。这可确保准确提取表格和数字等复杂的文档元素。Docling 使用先进的人工智能驱动方法提取表格,主要是利用其定制的 TableFormer 模型。
- 统一文档表示法:Docling 使用统一且富有表现力的格式来表示解析后的文档,使其更易于在下游应用程序中进行处理和分析。
- 人工智能就绪集成:该工具包与 LangChain 和 LlamaIndex 等流行的人工智能框架无缝集成,使其成为检索增强生成(RAG)和问题解答系统等应用的理想选择。
- 本地执行:它支持本地执行,可在空中封闭环境中安全处理敏感数据
- 高效性能:Docling 设计用于在对资源要求最低的商品硬件上运行,在可能的情况下避免使用传统的 OCR,将处理速度提高 30 倍,同时减少错误。
- 模块化架构:其模块化设计允许轻松定制和扩展新功能或模型,以满足不同用例的需求
- 开源可访问性:与 Watson Document Understanding 等专有工具不同,Docling 在 MIT 许可下开源,允许开发人员自由使用、定制并将其集成到工作流程中,而无需锁定供应商或支付额外费用。
Docling 提供可选的 OCR 支持,例如,覆盖扫描的 PDF 或嵌入页面的 bitmap 图像内容。Docling 依赖于 EasyOCR,这是一个流行的第三方 OCR 库,支持多种语言。这些功能使 Docling 成为生成式人工智能工作流程中文档解析和准备的全面解决方案。
使用Docling构建多模态RAG系统
在本文中,我们将首先使用 Docling 从 PDF 中提取各种数据–文本、图像和表格。对于提取的图像,我们将使用视觉语言模型生成图像描述,并将这些图像文本描述与 PDF 中原始文本内容的文本数据和提取的表格文本一起保存在我们的 VectorDB 中。之后,我们将建立一个 RAG 系统,使用矢量数据库进行检索,并通过 Ollama 使用 LLM(Phi 4)从 PDF 文档中进行查询。
通过Google Colab使用T4 GPU实现Python上机操作
您可以在此处找到包含所有步骤的 Colab Notebook。
步骤 1. 安装库
我们首先安装必要的库
!pip install docling #Following code added to avoid an error in installation - can be removed if not needed import locale def getpreferredencoding(do_setlocale = True): return "UTF-8" locale.getpreferredencoding = getpreferredencoding !pip install langchain-huggingfaceCopy Code
步骤 2. 加载转换器对象
这段代码准备了一个文档转换器,用于处理不带 OCR 但能生成图像的 PDF 文件。然后,它将这种转换应用于指定的 PDF 文件,并将结果存储在字典中。
我们使用这个有大量图表的 PDF 文件(我们将其保存在当前工作目录中,名为“accenture.pdf”)来测试使用 Docling 进行的多模态检索。
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
pdf_pipeline_options = PdfPipelineOptions(do_ocr=False,generate_picture_images=True,)
format_options = {InputFormat.PDF: PdfFormatOption(pipeline_options=pdf_pipeline_options)}
converter = DocumentConverter(format_options=format_options)
sources = [ "/content/accenture.pdf",]
conversions = {source: converter.convert(source=source).document for source in sources}Copy Code
步骤 3. 加载嵌入文本的模型
from langchain_huggingface.embeddings import HuggingFaceEmbeddings from transformers import * embeddings_model_path = "ibm-granite/granite-embedding-30m-english" embeddings_model = HuggingFaceEmbeddings(model_name=embeddings_model_path,) embeddings_tokenizer = AutoTokenizer.from_pretrained(embeddings_model_path)Copy Code
步骤 4. 对文档中的文本进行分块
下面的代码用于文档处理管道。它将上一步转换后的文档分解成更小的块,表格除外(稍后单独处理)。然后将每个小块封装成一个带有特定元数据的文档对象。代码处理转换后的文档时,会将文档分割成若干小块,跳过表格,并为每个小块创建带有元数据的新文档对象。
from docling_core.transforms.chunker.hybrid_chunker import HybridChunker
from docling_core.types.doc.document import TableItem
from langchain_core.documents import Document
doc_id = 0
texts: list[Document] = []
for source, docling_document in conversions.items():
for chunk in HybridChunker(tokenizer=embeddings_tokenizer).chunk(docling_document):
items = chunk.meta.doc_items
if len(items) == 1 and isinstance(items[0], TableItem):
continue # we will process tables later
refs = " ".join(map(lambda item: item.get_ref().cref, items))
text = chunk.text
document = Document(page_content=text,metadata={"doc_id": (doc_id:=doc_id+1),"source": source,"ref": refs,},)
texts.append(document)
print(f"{len(texts)} text document chunks created")Copy Code
步骤 5. 处理文档中的表格
下面的代码旨在处理转换后文档中的表格。它提取表格,将其转换为 Markdown 格式,并将每个表格封装为一个带有特定元数据的文档对象。
from docling_core.types.doc.labels import DocItemLabel
doc_id = len(texts)
tables: list[Document] = []
for source, docling_document in conversions.items():
for table in docling_document.tables:
if table.label in [DocItemLabel.TABLE]:
ref = table.get_ref().cref
text = table.export_to_markdown()
document = Document(
page_content=text,
metadata={
"doc_id": (doc_id:=doc_id+1),
"source": source,
"ref": ref
},
)
tables.append(document)
print(f"{len(tables)} table documents created")Copy Code
步骤 6. 定义将PDF图像转换为base64格式的函数
import base64
import io
import PIL.Image
import PIL.ImageOps
from IPython.display import display
def encode_image(image: PIL.Image.Image, format: str = "png") -> str:
image = PIL.ImageOps.exif_transpose(image) or image
image = image.convert("RGB")
buffer = io.BytesIO()
image.save(buffer, format)
encoding = base64.b64encode(buffer.getvalue()).decode("utf-8")
return encodingCopy Code
步骤 7. 从Ollama提取模型用于分析PDF中的图像
我们将使用 Ollama 的视觉语言模型来分析从 PDF 中提取的图像,并为每张图像生成描述。为方便使用 Ollama 模型,我们将安装以下库,并在提取模型前启动 Ollama 服务器,具体代码如下。
!sudo apt update !sudo apt install -y pciutils !pip install langchain-ollama !curl -fsSL https://ollama.com/install.sh | sh !pip install ollama==0.4.2 !pip install langchain-community #Enabling threading to start ollama server in a non blocking manner import threading import subprocess import time def run_ollama_serve(): subprocess.Popen(["ollama", "serve"]) thread = threading.Thread(target=run_ollama_serve) thread.start() time.sleep(5)Copy Code
步骤 8. 为从PDF中提取的每张图像生成说明
下面的代码旨在处理转换文档中的图像。它提取图像,使用视觉模型(通过 Ollama 生成 llama3.2-vision)为每张图像生成描述性文本,并将这些文本封装到带有特定元数据的文档对象中。下面是详细说明:
从 Ollama 提取“llama3.2-vision”模型。
llama pull llama3.2-visionCopy Code
def encode_image(image: PIL.Image.Image, format: str = "png") -> str:
image = PIL.ImageOps.exif_transpose(image) or image
image = image.convert("RGB")
buffer = io.BytesIO()
image.save(buffer, format)
encoding = base64.b64encode(buffer.getvalue()).decode("utf-8")
return encodingCopy Code
import ollama
pictures: list[Document] = []
doc_id = len(texts) + len(tables)
for source, docling_document in conversions.items():
for picture in docling_document.pictures:
ref = picture.get_ref().cref
image = picture.get_image(docling_document)
if image:
print(image)
response = ollama.chat(
model="llama3.2-vision",
messages=[{
"role": "user",
"content": "Describe this image?",
"images": [encode_image(image)]
}],
)
text = response['message']['content'].strip()
document = Document(
page_content=text,
metadata={
"doc_id": (doc_id:=doc_id+1),
"source": source,
"ref": ref,
},
)
pictures.append(document)
print(f"{len(pictures)} image descriptions created")Copy Code
import itertools
from docling_core.types.doc.document import RefItem
# Print all created documents
for document in itertools.chain(texts, tables):
print(f"Document ID: {document.metadata['doc_id']}")
print(f"Source: {document.metadata['source']}")
print(f"Content:\n{document.page_content}")
print("=" * 80) # Separator for clarity
for document in pictures:
print(f"Document ID: {document.metadata['doc_id']}")
source = document.metadata['source']
print(f"Source: {source}")
print(f"Content:\n{document.page_content}")
docling_document = conversions[source]
ref = document.metadata['ref']
picture = RefItem(cref=ref).resolve(docling_document)
image = picture.get_image(docling_document)
print("Image:")
display(image)
print("=" * 80) # Separator for clarityCopy Code
步骤 9. 存储在Milvus向量数据库中
Milvus 是一个高性能矢量数据库,专为扩大规模而设计。它通过有效组织和搜索大量非结构化数据(如文本、图像和多模态信息),为人工智能应用提供动力。我们首先安装 langchain-milvus 库,然后在向量数据库中存储文本、表格和图片。在定义矢量数据库的同时,我们还传递了嵌入模型,以便矢量数据库在存储之前将提取的所有文本(包括表格和图片说明中的数据)转换为嵌入。
!pip install langchain_milvus
import tempfile
from langchain_core.vectorstores import VectorStore
from langchain_milvus import Milvus
db_file = tempfile.NamedTemporaryFile(prefix="vectorstore_", suffix=".db", delete=False).name
vector_db: VectorStore = Milvus(embedding_function=embeddings_model,connection_args={"uri": db_file},auto_id=True,enable_dynamic_field=True,index_params={"index_type": "AUTOINDEX"},)
#add all the LangChain documents for the text, tables and image descriptions to the vector database
import itertools
documents = list(itertools.chain(texts, tables, pictures))
ids = vector_db.add_documents(documents)
print(f"{len(ids)} documents added to the vector database")Copy Code
步骤 10. 使用Phi 4模型的检索增强生成功能查询模型
在下面的代码中,我们首先从 Ollama 中提取“Phi 4”模型,然后将其作为 RAG 系统中的 LLM,用于根据查询从向量数据库中检索相关上下文后生成响应。
#Pulling the Ollama model for querying
llama pull phi4
#Querying
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatOllama
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
retriever = vector_db.as_retriever()
# Prompt
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# Local LLM
ollama_llm = "phi4"
model_local = ChatOllama(model=ollama_llm)
# Chain
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model_local
| StrOutputParser()
)
chain.invoke("How much worth in dollars is Strategy & Conslution in Services?")
Copy Code
输出
According to the context provided, the 'Technology & Strategy/Consulting' section of the company's operations generated a value of $15 billion.
从文档中的下图可以看出,我们的多模态 RAG 系统的响应是正确的。通过 Docling,我们从图表中正确提取了信息,因此检索系统能够为我们提供准确的回复。
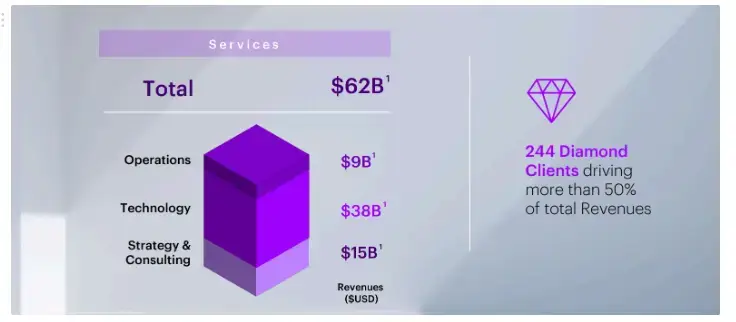
原始 PDF 文件中的图表
通过更多查询分析我们的RAG系统
德国的收入是多少?
The revenue in Germany, according to the provided context, is $3 billion. This information is listed under the 'Country-Wise Revenue' section of the document: \n\n. **Germany**: $3 billion\n\nIf you need any further details or have additional questions, feel free to ask!
从文档中的下图可以看出,我们的多模态 RAG 系统的响应是正确的。通过 Docling,我们从图表中正确提取了信息,因此检索系统能够为我们提供准确的回复。
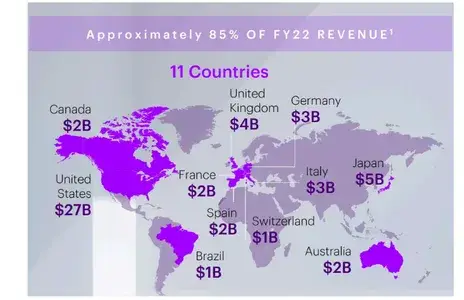
原始 PDF 格式的图表
Cloud FY19的收入是多少?
The Cloud FY19 revenue, as provided in the document context, was $11 billion. This information is found in the first table under the section titled 'Cloud' where it states:\n\nFY19: $11B\n\nThis indicates that the revenue from cloud services for fiscal year 2019 was $11 billion.
从文档中的下表可以看出,我们的多模态 RAG 系统的响应是正确的。通过 Docling,我们从图表中正确提取了信息,因此检索系统能够为我们提供准确的回复。
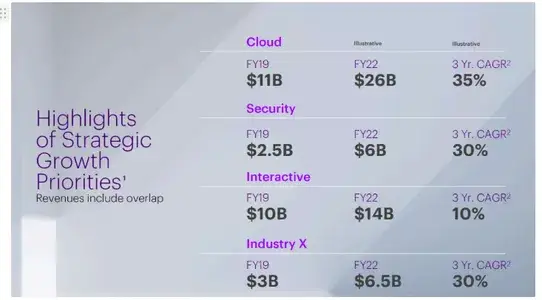
原始 PDF 中的图表
行业 X 3 年复合年增长率是多少?
Based on the provided context from the documents in Accenture’s PDF:\n\n-In Document withdoc_id15 and Document withdoc_id3, both mention IndustryX.\n-The relevant information is found under a section about revenue growthfor Industry X:\n\n**Document 15** indicates: "FY19 $10B Industry X FY19 $3BFY22 $6.5B 3 Yr. CAGR 2 30%"\n\n**Document 3** reiterates this with similarwording: "Cloud = FY19 $10B Industry X FY19. , Illustrative = . , Cloud =$3B. , Illustrative = FY22 $6.5B. , Illustrative = 3 Yr. CAGR 2 30%"\n\nFromthese excerpts, the 3-year compound annual growth rate (CAGR) for Industry Xis **30%."**.\n\n
从文档中的上表可以看出,我们的多模态 RAG 系统的响应是正确的。通过 Docling,信息被正确地从图表中提取出来,因此检索系统能够为我们提供准确的回应
小结
总之,Docling 是将非结构化数据转化为机器可读格式的强大工具,使其成为多模态检索-增强生成(RAG)等应用的重要资源。通过利用先进的人工智能模型并与流行的人工智能框架无缝集成,Docling 增强了高效处理和查询复杂文档的能力。Docling 的开源特性,加上通用格式支持和模块化架构,使其成为企业在实际应用案例中寻求利用人工智能生成技术的理想解决方案。
- Docling 工具包:IBM 的开源工具,用于从 PDF、DOCX 和图像中提取结构化数据(JSON、Markdown),实现无缝人工智能集成。
- 高级人工智能模型:使用 Layout Analysis 和 TableFormer 进行准确的文档处理,减少对传统 OCR 的依赖。
- 人工智能框架集成:可与 LangChain 和 LlamaIndex 协同工作,是 RAG 系统的理想选择,可提供经济高效的人工智能驱动型洞察力。
- 开源和可定制:获得麻省理工学院许可,模块化,可适应各种用例,不受供应商锁定。
免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。












暂无评论内容