

人工智能图像生成技术已经取得了长足的进步。过去,早期的算法只能生成模糊、抽象的图片。但如今,这些系统已经变得无比先进,能够生成逼真的照片、令人惊叹的艺术作品,以及介于两者之间的一切。现在,在 2025 年,人工智能图像生成模型已经达到了一个全新的水平,超越了我们之前所看到的任何东西。它们正在以我们从未想象过的方式改变数字艺术、革新广告业、重塑娱乐业。
本文旨在讨论目前主导市场的最强、极富创造力的图像生成模型。它在逼真度、创意多变性、道德实施以及与各种在制品的配合使用等不同方面都带来了令人难以置信的表现。数字艺术家和营销人员、内容创作者以及有兴趣了解这些工具及其优势的好奇者,在以图像为基础的数字生态系统中的相关性日益增强。
2025年最佳AI图像生成器
| 工具 | 价格 | 最大亮点 |
|---|---|---|
| Midjourney | 10 美元/月起 | 非凡的逼真效果 |
| DALL-E 3 (OpenAI) | 20 美元/月(ChatGPT Plus) | 对话式图像创建 |
| Flux AI | 免费和付费 API(Pro 模型) | 高速图像生成 |
| Stable Diffusion | 免费(自行托管),付费 10 美元/月起 | 完全开源和可定制 |
| Imagen | 免费(通过谷歌),付费从 5.99 美元/月起 | 卓越的文本渲染 |
| Adobe Firefly | 免费(25 个点数),付费 4.99 美元/月起 | 创意套件集成 |
| Leonardo.AI | 免费(150 个tokens/天),付费 10 美元/月起 | 多种艺术风格 |
1. Midjourney

Source: Midjourney
规格
- 免费计划:不适用
- 付费计划:起价 10 美元/月
- 最新版本:6.1(2024 年 7 月发布)
- 界面:基于 Discord 和网页用户界面
- 图像分辨率:最高 1024×1024(通过放大可达到更高分辨率)
Midjourney 已成为当今首屈一指的人工智能图像生成系统之一。Midjourney 主要通过 Discord 运行,同时也提供网页界面,擅长创建高度逼真、艺术感十足的图像。该平台使用基于扩散的模型,在不同的视觉数据集上进行训练,其准确呈现人类特征的能力尤其受到认可,而这正是许多其他系统难以解决的难题。2024 年中期发布的 6.1 版对皮肤纹理和整体连贯性进行了重大改进,同时将生成时间缩短了约 25%。
购买理由
- 非凡的逼真度,尤其是人物模型
- 通过大量参数命令实现精细控制
- 强大的艺术造型能力
- 稳定的高质量输出
- 功能强大的网络用户界面,界面直观
- 社区展示和来自其他用户的灵感
拒绝理由
- 没有免费计划
- 掌握参数的学习曲线较长
- 训练数据源的透明度有限
- 默认情况下公开生成(隐私要求更高级别的计划)
- Discord 界面可能会让初学者不知所措
独家事实
Midjourney 是首批解决臭名昭著的 “手指问题 ”的人工智能图像生成器之一,在竞争对手还在生成扭曲的附肢和不正确的数字计数时,Midjourney 能持续生成解剖学上正确的人手。这一成就代表了人工智能图像生成逼真度的重大突破,并帮助 Midjourney 树立了高质量的声誉。
它的独特之处是什么?
Midjourney 的真正与众不同之处在于它的参数系统,该系统为图像生成提供了无与伦比的控制。用户可以使用特定的命令来修改创作的几乎所有方面–从长宽比和风格化水平到参考图像的影响。
“–weight” 参数可以精确平衡提示中的不同元素,而 “–no” 参数则有助于排除不需要的特征。这种细粒度的控制,再加上 Midjourney 解读和执行创意构想的卓越能力,使其对专业创意人员和那些追求精确而非近似效果的人尤为重要。
试试看
提示词:A futuristic cityscape at sunset with flying vehicles, holographic billboards, and a single figure standing on a rooftop overlooking the scene.

(Image credit: Midjourney/Future AI)
2. DALL-E 3 (OpenAI)

Source: OpenAI
规格
- 免费计划:不适用
- 付费计划:订购 ChatGPT Plus 后每月 20 美元
- 最新版本:DALL-E 3(2023 年 10 月发布)
- 界面:与 ChatGPT 集成
- 图像分辨率:1024×1024(标准)
- 每日生成限制:Plus 用户每日 50 张图片
DALL-E 3 是 OpenAI 首创的文本到图像生成系统的第三次迭代。它建立在 ChatGPT 的基础上,利用语言模型的能力来解释和完善提示,这标志着与以前版本的重大不同。这种整合使用户能够通过自然对话而不是复杂的提示工程来构思和迭代图像创意。DALL-E 3 在理解细致入微的指令和生成与用户意图非常吻合的连贯、详细的图像方面取得了显著的进步。该模型采用基于扩散的方法,结合 CLIP(对比语言-图像预训练)技术,对输出结果进行评估和改进。
购买理由
- 对话式界面使图像生成更加直观
- 出色的文本渲染能力
- 基于提示的编辑和完善
- 对复杂指令有很强的理解能力
- 与 ChatGPT 的推理能力无缝集成
- 通过绘图界面进行图像内编辑
拒绝理由
- 没有免费计划
- 偶尔会偏离具体的提示细节
- 与专业平台相比,定制选项有限
- 仅限 ChatGPT Plus 用户使用
- 安全过滤器有时限制过多
独家事实
DALL-E 3 标志着 OpenAI 图像生成功能在架构上的重大转变,从独立系统转变为与其语言模型深度集成的系统。这种整合使系统能够利用 ChatGPT 的推理能力,自动将简短的提示扩展为详细的描述,基本上是在执行自己的提示工程。这种方法使 DALL-E 3 解决了人工智能图像生成工具的专业用户与普通用户之间以前存在的 “提示工程鸿沟”。
它的独特之处是什么?
DALL-E 3 的真正与众不同之处在于其对话式图像创建方法。DALL-E 3 不要求用户掌握复杂的提示语法,而是允许自然语言交互,用户可以简单地描述他们想要什么,然后通过对话加以完善。这使得创作过程更加容易和直观,尤其是对于人工智能图像生成的新手来说。
该模型能够从正在进行的对话中理解上下文,并将这种理解应用到图像生成中,从而创造出更具协作性的创意体验。此外,DALL-E 3 在渲染图像中的文字方面具有独特的优势a,这对许多人工智能图像生成器来说都是众所周知的挑战,因此它在创建海报、书籍封面或宣传材料等需要可读文字元素的内容时具有明显的优势。
试试看
提示词:A futuristic cityscape at sunset with flying vehicles, holographic billboards, and a single figure standing on a rooftop overlooking the scene.

(Image credit: Dall E 3)
3. Flux AI

规格
- 免费计划:可用(Flux.1 Dev 和 Flux.1 Schnell)
- 付费计划:专业版模型的 API 访问权限
- 最新版本:Flux 1.1 Pro Ultra
- 界面:API 访问和本地推理
- 图像分辨率:高达 1024×1024
- 模型大小:12B 参数
Flux AI 由 Black Forest Labs 开发,代表了开源图像生成能力的重大进步。Flux 基于强大的 120 亿参数变压器架构,可直接与 SD3 Ultra、Midjourney V6.0 和 DALL-E 3 HD 等领先模型竞争,甚至超越它们。该模型采用了复杂的流水线,包括用于理解提示的 CLIP、用于处理复杂提示的 T5-XXL 编码器、用于空间关系的带有 MMDiT 架构的 FluxTransformer2DM 模型以及用于最终图像重建的 VAE。Flux 有多个版本:旗舰版 Flux 1.1 Pro Ultra 可提供高质量;Flux.1 Pro 适用于专业应用;Flux.1 Dev 适用于研究人员和设计人员(开源供非商业使用);Flux.1 Schnell 适用于超高速生成,只需 5 个时间戳即可提供高质量输出。
购买理由
- 在多种使用情况下具有卓越的多功能性
- 可用于实验的开源变体
- 显著的速度-质量比,尤其是 Schnell 变体
- 在产品摄影和用户界面设计方面表现出色
- 通过引导尺度和推理步骤实现精细控制
- 结合 CLIP 和 T5 理解的先进架构
拒绝理由
- 计算要求高(推理需要 38GB+ VRAM)
- 难以进行图像内文本渲染
- 专业版需要访问 API 而非直接使用
- 需要调整参数以获得最佳结果
- 与对话式界面相比,对初学者而言不够直观
独家事实
Flux 的独特架构采用了流量匹配和时间戳采样技术,大大提高了生成效率。因此,Flux.1 Schnell 变体只需 5 个推理步骤就能生成高质量图像,是目前速度最快的高质量图像生成器之一,同时还能保持出色的输出质量。这种效率对于速度与质量同样重要的实时应用和快速原型设计方案尤为重要。
它的独特之处是什么?
Flux 的独特之处在于它在易用性、性能和多功能性之间取得了出色的平衡。与许多竞争对手不同,Flux 同时提供面向研究人员的开源变体和面向专业人员的高级模型,以满足不同用户的需求。它的架构在用户界面设计、YouTube 缩略图和产品摄影等专业领域表现尤为突出,而在这些领域,其他模型往往难以保持一致性。该模型的指导尺度参数可微调(最佳效果在 2.0-3.0 之间),用户可精确控制对及时性和创造性的诠释。这使得同一模型既能实现高精度的商业作品,也能产生更具艺术性和解释性的作品。此外,Flux 采用现代扩散技术,与计算密集型竞争对手相比,具有显著的效率优势。
试试看
提示词:A futuristic cityscape at sunset with flying vehicles, holographic billboards, and a single figure standing on a rooftop overlooking the scene.

(Image credit: Flux AI)
4. Stable Diffusion

Source: Stability AI
规格
- 免费计划:是(可自行托管)
- 付费计划:各种服务起价为 10 美元/月(DreamStudio、RunwayML)
- 最新版本:3.0(2025 年 2 月发布)
- 界面:基于网络、桌面应用程序和应用程序接口
- 图像分辨率:高达 2048×2048(微调后更高)
Stable Diffusion 是由 Stability AI、慕尼黑路德维希-马克西米利安大学 CompVis 小组和 Runway AI 合作开发的开创性开源潜在扩散模型。与竞争对手不同的是,Stable Diffusion 为用户提供了完全的访问权限,允许他们使用、修改和重新发布模型。这种开放性促进了一个充满活力的定制实施和应用生态系统。该模型的工作原理是将文本或图像提示翻译成低维度的潜在空间,通过 U-Net 架构中的多个步骤逐步对表示进行去噪处理,然后将其解码回详细图像。除了基本的图像生成外,稳定扩散技术还擅长图像放大、内绘(恢复受损图像或添加对象)和外绘(扩展到原始画布之外)。
购买理由
- 完全开源且可定制
- 可在本地消费级硬件上运行
- 自托管时无内容限制
- 活跃的社区开发工具和扩展功能
- 除基本图像生成功能外,还具有多种应用功能
- 自托管时无使用限制
拒绝理由
- 需要技术知识才能实现最佳的自托管效果
- 本地安装对硬件要求较高
- 生成时间通常比基于云的替代方案慢
- 对于没有技术技能的初学者来说,用户界面不够友好
- 质量可能因实施情况和硬件而异
- 可能需要及时的工程技能才能达到最佳效果
独家事实
Stability AI 筹集了超过 1 亿美元的资金来开发 Stable Diffusion,但随后做出了一个激进的决定,将其作为开源软件发布–此举大大加快了人工智能艺术技术的民主化进程。这一决定在人工智能社区引发了争议,但最终导致成千上万的开发者开发出了创新应用和改进方案,而这在闭源模式下是不可能实现的。
它的独特之处是什么?
Stable Diffusion 的真正与众不同之处在于其前所未有的灵活性和可访问性。作为一种开源模式,它催生了整个专门实施生态系统,从 ComfyUI 和 Stable Diffusion WebUI 到 DreamStudio 等商业平台。
这种灵活性允许用户针对特定的艺术风格对模型进行微调,在自定义数据集上进行训练,或修改其架构以满足特定需求。该模型能够在潜在空间而非像素空间工作,这使它的计算效率大大高于早期的扩散模型,能够在消费级硬件上运行。
这种开放性、高效性和多功能性的结合使稳定扩散成为无数人工智能艺术应用和服务的基础,从基本的图像生成器到复杂的设计工具,不一而足。
试试看
提示词:A futuristic cityscape at sunset with flying vehicles, holographic billboards, and a single figure standing on a rooftop overlooking the scene.

(Image credit: Stable Diffusion)
5. Imagen

Source: DeepMind
规格
- 免费计划:是(通过 Google Gemini 和 ImageFX)
- 付费计划:通过 NightCafe Studio 提供(起价 5.99 美元/月)
- 最新版本:Imagen 3(2024 年 8 月发布)
- 界面:与谷歌产品(Gemini、ImageFX、Docs、Slides)和第三方平台集成
- 图像分辨率:最高 1024×1024(特定实现时更高)
Imagen 是谷歌 DeepMind 的强大文本到图像生成模型,已迅速成为行业领导者。最新迭代的 Imagen 3 以其卓越的质量和多功能性代表了人工智能图像生成技术的重大进步。Imagen 3 的与众不同之处在于它与谷歌生态系统的无缝集成–从双子座到谷歌文档和幻灯片,使日常用户也能获得专业品质的人工智能图像。
该模型尤其擅长逼真的风景、复杂的细节和精确的文字渲染–这是许多同类模型所面临的挑战。Imagen 3 能出色地处理文本提示,创建的图像与用户的描述非常吻合,同时还能提供往往超出预期的创意诠释。
购买理由
- 卓越的逼真画质,尤其是在风景和自然场景方面
- 与竞争对手相比,文本渲染能力更胜一筹
- 与谷歌生产力套件无缝集成
- 可通过多个免费平台高度访问
- ImageFX 等平台上直观的编辑工具
- 内置的建议功能可帮助用户更好地理解提示
拒绝理由
- 与某些竞争对手相比,对特定参数的控制较少
- 免费实施中的自定义选项有限
- 复杂的多元素提示结果不一致
- 更高质量的输出可能需要付费服务,如 NightCafe
- 谷歌的内容政策可能会限制某些类型的创意生成
- 与谷歌数据收集行为有关的隐私问题
独家事实
Imagen 3 是首个在生成的图像中实现近乎完美的文本渲染的主要人工智能图像生成器,解决了自其诞生以来一直困扰该行业的问题。这一突破来自 DeepMind 的新颖方法,即在训练过程中将文本作为一种特殊的视觉元素,从而使模型能够以前所未有的准确度理解字符与其视觉表现之间的关系。
它的独特之处是什么?
Imagen 3 的独特之处在于其无与伦比的可访问性和与谷歌生态系统的整合。其他模型可能会提供独立的体验,而 Imagen 则将专业级人工智能图像直接引入用户已经在使用的生产力工具中。这种整合策略将 Imagen 从一个单纯的图像生成器转变为一个实用的创意助手,增强了现有的工作流程。
该模型能够通过 Gemini 等平台中的自然语言指令接收反馈并迭代改进图像,从而创造出一种非常直观的协作式创意流程。此外,Imagen 在 ImageFX 中的应用通过简单的界面提供了复杂的编辑功能,允许用户对图像的特定区域进行有针对性的修改–这一功能极大地扩展了其对普通用户和专业人士的实际应用。
试试看
提示词:A futuristic cityscape at sunset with flying vehicles, holographic billboards, and a single figure standing on a rooftop overlooking the scene.

(Image credit: Imagen)
6. Adobe Firefly

Source: Adobe Firefly
规格
- 免费计划:是(仅限 25 个生成点数)
- 付费计划:4.99 美元/月(100 个点数);也包含在创意云订阅中
- 最新版本:Firefly Image 2(包含矢量、设计和视频模型)
- 界面:基于网络的应用程序,集成到 Adobe Creative Suite 中
- 图像分辨率:高达 2048×2048(因实施情况而异)
Adobe Firefly 代表着这家创意软件巨头全面进军人工智能生成领域,提供的不仅是一个模型,而是一个完整的人工智能工具生态系统。与大多数竞争对手不同,Firefly 包含四个不同的模型: 图像、矢量、设计和视频(测试版)。Firefly 的突出特点是无缝集成了 Adobe 的创意生态系统,既可以作为独立的网络应用程序使用,也可以为 Photoshop、Illustrator、Premiere Pro 和 Adobe Express 中的高级工具提供支持。
该系统专门针对 Adobe Stock 图像、公共领域内容和公开授权作品进行了培训,因此对于担心版权问题的专业人士来说,它是一种商业上更安全的选择。Firefly 的功能超出了基本图像生成的范围,包括 Photoshop 中的生成填充和扩展、Illustrator 中的矢量生成,甚至 Premiere Pro 中的视频扩展。
购买理由
- 通过适当的许可和内容验证确保商业安全
- 与 Adobe Creative Cloud 应用程序无缝集成
- 强大的上下文感知编辑工具,如生成填充工具
- 首个具有专用矢量生成功能的主流 AI 系统
- 风格匹配功能可实现品牌一致性
- 内容证书和元数据实现透明化
拒绝理由
- 考虑到创意云订阅成本,价格昂贵
- 免费层级有限(只有 25 个生成点数)
- 原始图像质量一般不如竞争对手出色
- 在专业应用程序中使用时,学习曲线较陡峭
- 复杂设计的矢量生成质量不稳定
- 视频模型仍处于早期测试阶段,有很大的局限性
独家事实
Adobe Firefly 是首款采用内容凭证(图像的数字 “营养标签”)的主要人工智能图像生成器,可显示创建或编辑图像的方式和时间。该系统是与 “内容真实性倡议”(Content Authenticity Initiative)合作开发的,在生成的图像中嵌入了防篡改元数据,允许用户验证图像的来源和编辑历史,随着人们对人工智能生成的虚假信息的担忧与日俱增,该系统有可能彻底改变人们对数字媒体的信任。
它的独特之处是什么?
Adobe Firefly 与其他人工智能图像生成器的真正区别在于其专业的工作流程集成。当竞争对手专注于创造独立的体验时,Adobe 将 Firefly 定位为现有创意流程的增强版,而不是替代品。Photoshop 中的 “生成填充”(Generative Fill)功能就是这种方法的典范–允许艺术家将人工智能生成的元素与传统编辑技术无缝融合,同时保持对最终结果的完全控制。这种整合策略将 Firefly 从一种新奇的工具转变为一种实用的生产力工具,自然地融入到专业工作流程中。
此外,Adobe 还致力于开展合乎道德的人工智能培训和透明的内容归属,以解决业界日益关注的版权和归属问题。对于既需要强大的人工智能功能又需要商业安全的专业创作人员来说,Firefly 提供了一个独特的组合,目前市场上还没有真正的同类产品。
试试看
提示词:A futuristic cityscape at sunset with flying vehicles, holographic billboards, and a single figure standing on a rooftop overlooking the scene.

(Image credit: Adobe Firefly)
7. Leonardo.AI
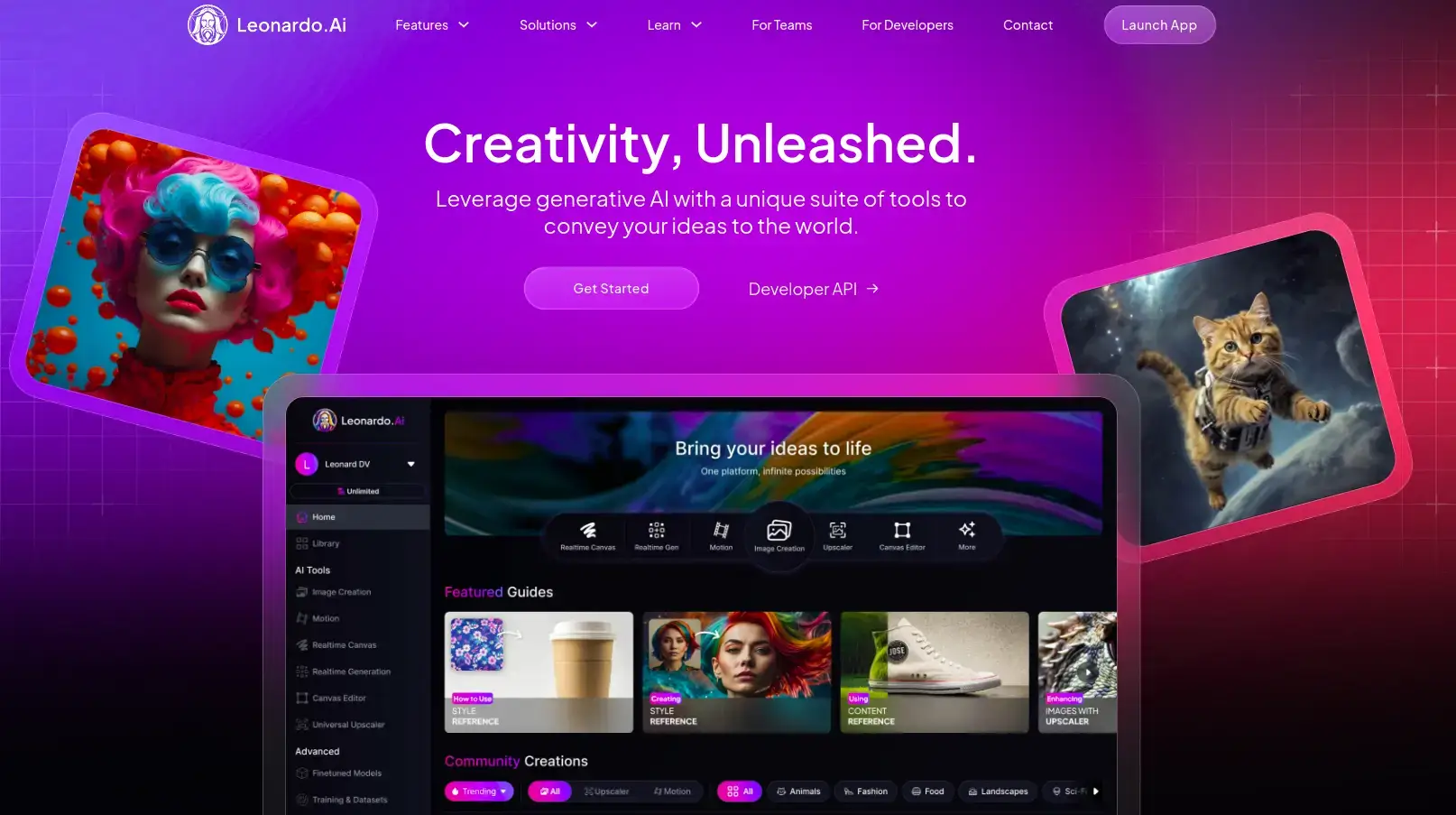
Source: Leonardo AI
规格
- 免费计划:每天 150 个代币(约 18-30 张图片)
- 付费计划:起价 10 美元/月(学徒)、24 美元/月(工匠无限)、48 美元/月(大师无限)
- 界面:基于网络的综合工具
- 图像分辨率:多种选项可供选择,可使用通用升级程序进行增强
- 用户:超过 120 万名艺术家,共生成 10 亿多幅艺术作品
Leonardo.AI 已迅速成为人工智能图像生成领域的领先竞争者,可根据文本描述提供制作品质的图像和视频。Leonardo 最初专注于游戏应用,在保持逼真度方面优势的同时,还将其功能扩展到多个艺术领域。该平台提供十种不同的预设模型,包括 Leonardo Phoenix(基础模型)、Anime、Cinematic Kino、Concept Art、Graphic Design、Illustrative Albedo、Leonardo Lightning、Lifelike Vision、Portrait Perfect 和 Stock Photography,每种模型都针对特定的创意需求进行了优化。
主要功能
- 图像生成:根据文本提示创建高质量图像,提供多种风格选项
- 实时画布:人工智能辅助绘图与实时增强
- 画布编辑器:全面的编辑工具,可进行详细的图像处理
- 实时生成:在输入提示时看到图像形成
- 通用放大器:提高图像分辨率和质量
- Image2Motion:将静态图像转换为电影序列
购买理由
- 直观、友好的用户界面
- 适合不同艺术风格的多种 AI 模型
- 可训练自定义模型
- 快速稳定的性能
- 基本生成之外的全面编辑工具
- 基于代币的系统,提供合理的免费层级
拒绝理由
- 代币消耗量因任务而异,难以计算
- 某些模型存在人工智能偏差
- 视频生成功能仍处于早期开发阶段
- 在创建专门内容时,有些提示不一致
它的独特之处是什么?
Leonardo.AI 因其易用性与专业级输出的完美结合而脱颖而出。该平台的优势在于它在保持令人印象深刻的逼真度的同时,还具有跨越多种艺术风格的多功能性。实时画布和编辑功能使其超越了简单的文本到图像生成,提供了完整的创意工作流程。尤其对于营销人员和游戏开发人员来说,Leonardo 快速生成和完善概念艺术的能力大大节省了时间和资源。该平台的简约设计与社区展示相结合,为初学者和专业人士探索人工智能辅助创意创造了理想的环境。
试试看
提示词:A futuristic cityscape at sunset with flying vehicles, holographic billboards, and a single figure standing on a rooftop overlooking the scene.

小结
2025 年的 AI 图像生成模型已经从简单的新奇工具发展成为能够生成专业级视觉效果的复杂系统。每种模型都有其独特的优势–Midjourney 的逼真度、DALL-E 3 的直观提示、Stable Diffusion 的定制化,以及其他满足不同创意需求的模型。除了数字艺术之外,这些工具还在为各行各业带来变革,实现快速原型设计、个性化营销和简化设计工作流程。随着人工智能功能的不断完善,想象与现实之间的差距正在缩小,塑造着视觉创作的未来。
免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。












暂无评论内容