

由中国人工智能研究实验室 DeepSeek 在 High-Flyer 旗下开发的 DeepSeek V3 自 2024 年 12 月首次开源发布以来,一直是人工智能领域的佼佼者。它以高效、高性能和易用性著称,并在继续快速发展。DeepSeek V3 的最新更新于 2025 年 3 月 24 日推出,名为 “DeepSeek V3 0324”,带来了微妙而有影响的改进。让我们来看看这些更新,并试用新的 DeepSeek V3 模型。
小版本升级:DeepSeek V3 0324
- 此次升级增强了 DeepSeek 官网、手机应用和小程序的用户体验,默认关闭了“深度思考”模式。这表明升级的重点是简化交互,而不是改变核心功能。
- API 界面和使用方法保持不变,确保了开发人员的连续性。这意味着现有的集成(例如通过 model=’deepseek-chat’)无需调整。
- 没有提到重大的架构变化,这表明这是对现有的 671B 参数专家混合物(MoE)模型的改进,每个令牌可激活 37B 参数。
- 可用性:更新后的模型已在 DeepSeek 官方平台(网站、应用程序、小程序)和 HuggingFace 上上线。DeepSeek V3 0324 “的技术报告和权重可以在 MIT 许可下访问。
DeepSeek V3 0324表现如何?
X 上的一位用户在我的内部工作台上试用了新的DeepSeek V3,它在所有测试中的各项指标都有大幅提升。它现在是最好的非推理模型,超越了 Sonnet 3.5。
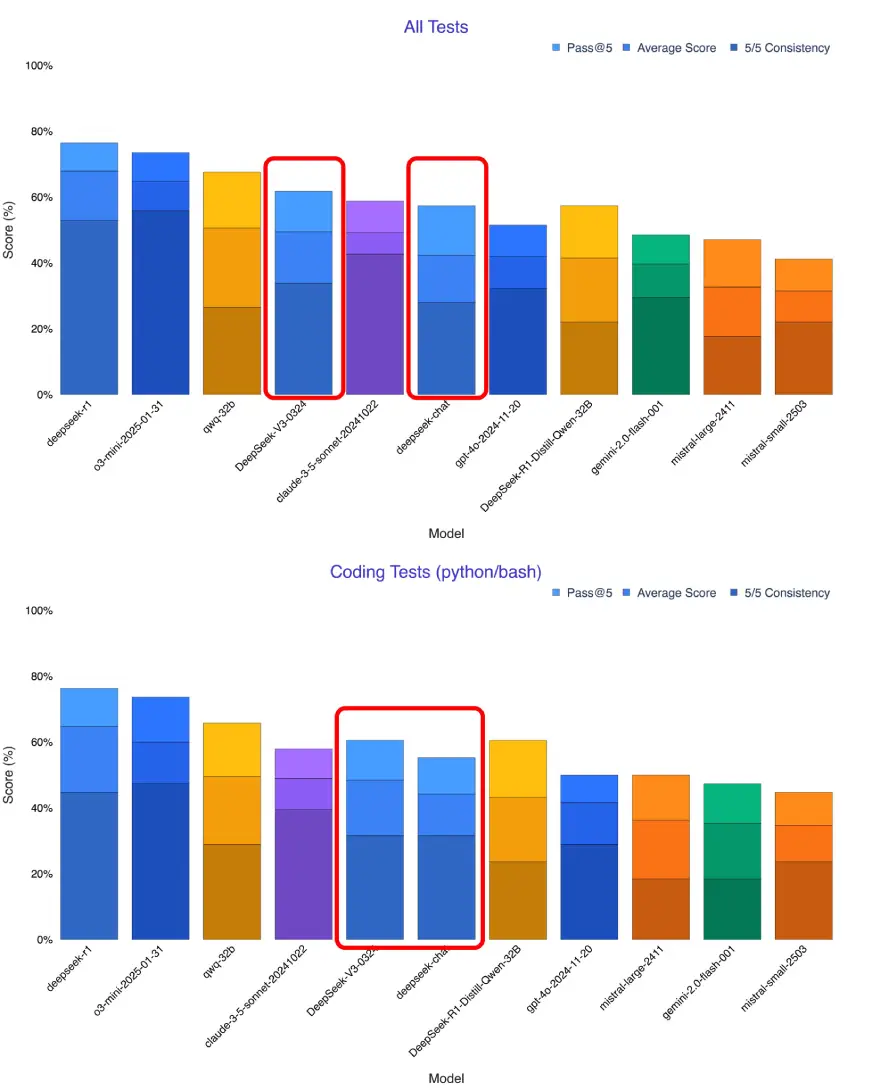
Source: X
DeepSeek V3 登上 Chatbot Arena 排行榜:
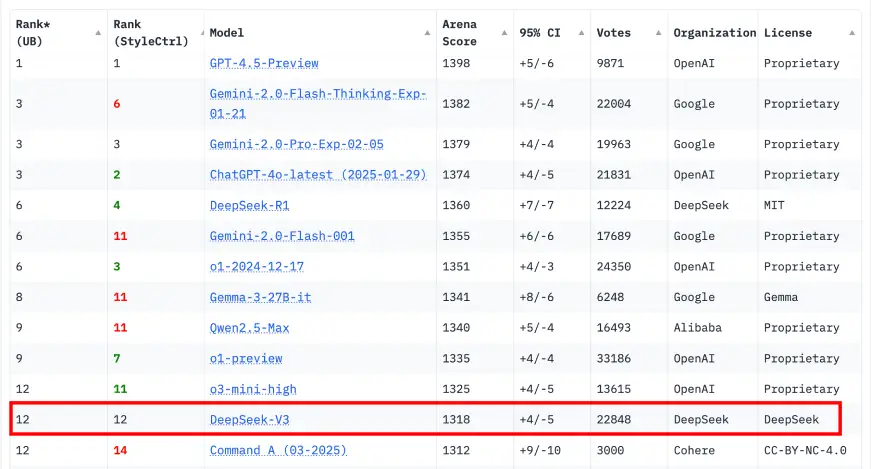
Source: lmarena
如何访问最新的DeepSeek V3?
- 网站:在 deepseek.com 免费测试更新的V3。
- 移动APP:可在 iOS 和 Android 上使用,已更新以反映 3 月 24 日的版本。
- API:在 api-docs.deepseek.com 上使用 model=’deepseek-chat’ 。定价仍为 0.14 美元/百万输入代币(推广期至 2025 年 2 月 8 日,但不排除延期的可能)。
- HuggingFace:从这里下载“DeepSeek V3 0324”权重和技术报告。
试用新版DeepSeek V3 0324
我将在本地和通过API使用更新后的DeepSeek模型。
使用llm-mlx插件在本地使用DeepSeek-V3-0324
安装步骤
以下是在您的机器上运行它所需的设备(假设您使用的是 llm CLI + mlx 后端):
!pip install llm !llm install llm-mlx !llm mlx download-model mlx-community/DeepSeek-V3-0324-4bit
这将:
- 安装核心
llmCLI - 添加 MLX 后端插件
- 下载 4 位量化模型(
DeepSeek-V3-0324-4bit)–更节省内存
在本地运行聊天提示
示例:
!llm chat -m mlx-community/DeepSeek-V3-0324-4bit 'Generate an SVG of a pelican riding a bicycle'
输出:
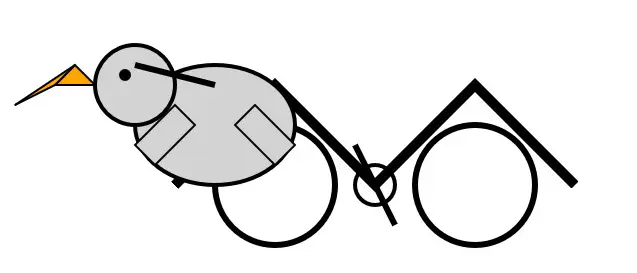
如果模型运行成功,它就会响应一个骑着自行车的鹈鹕的 SVG 片段–憨态可掬,光彩夺目。
通过API使用DeepSeek-V3-0324
安装所需软件包
!pip3 install openai
是的,尽管您使用的是 DeepSeek,但您使用的是与 OpenAI 兼容的 SDK 语法。
用于API交互的Python脚本
下面是脚本中经过清理的注释版本:
from openai import OpenAI
import time
# Timing setup
start_time = time.time()
# Initialize client with your DeepSeek API key and base URL
client = OpenAI(
api_key="Your_api_key",
base_url="https://api.deepseek.com" # This is important
)
# Send a streaming chat request
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "How many r's are there in Strawberry"},
],
stream=True
)
# Handle streamed response and collect metrics
prompt_tokens = 0
generated_tokens = 0
full_response = ""
for chunk in response:
if hasattr(chunk, "usage") and hasattr(chunk.usage, "prompt_tokens"):
prompt_tokens = chunk.usage.prompt_tokens
if hasattr(chunk, "choices") and hasattr(chunk.choices[0], "delta") and hasattr(chunk.choices[0].delta, "content"):
content = chunk.choices[0].delta.content
if content:
generated_tokens += 1
full_response += content
print(content, end="", flush=True)
# Performance tracking
end_time = time.time()
total_time = end_time - start_time
# Token/sec calculations
prompt_tps = prompt_tokens / total_time if prompt_tokens > 0 else 0
generation_tps = generated_tokens / total_time if generated_tokens > 0 else 0
# Output metrics
print("\n\n--- Performance Metrics ---")
print(f"Prompt: {prompt_tokens} tokens, {prompt_tps:.3f} tokens-per-sec")
print(f"Generation: {generated_tokens} tokens, {generation_tps:.3f} tokens-per-sec")
print(f"Total time: {total_time:.2f} seconds")
print(f"Full response length: {len(full_response)} characters")
输出
### Final AnswerAfter carefully examining each letter in "Strawberry," we find that the letter 'r' appears **3 times**.**Answer:** There are **3 r's** in the word "Strawberry."--- Performance Metrics ---Prompt: 17 tokens, 0.709 tokens-per-secGeneration: 576 tokens, 24.038 tokens-per-secTotal time: 23.96 secondsFull response length: 1923 characters
点击此处查看完整代码和输出结果。
使用DeepSeek-V3-0324构建数字营销网站
使用高级语言模型 DeepSeek-V3-0324,通过基于提示的代码生成方法,自动生成一个现代、时尚、小巧的数字营销登陆页面。
!pip3 install openai
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
import time
# Record the start time
start_time = time.time() # Add this line to initialize start_time
client = OpenAI(api_key="Your_API_KEY", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a Website Developer"},
{"role": "user", "content": "Code a modern small digital marketing Landing page"},
],
stream=True # This line makes the response a stream of events
)
# Initialize variables to track tokens and content
prompt_tokens = 0
generated_tokens = 0
full_response = ""
# Process the stream
for chunk in response:
# Track prompt tokens (usually only in first chunk)
if hasattr(chunk, "usage") and hasattr(chunk.usage, "prompt_tokens"):
prompt_tokens = chunk.usage.prompt_tokens
# Track generated content
if hasattr(chunk, "choices") and hasattr(chunk.choices[0], "delta") and hasattr(chunk.choices[0].delta, "content"):
content = chunk.choices[0].delta.content
if content:
generated_tokens += 1
full_response += content
print(content, end="", flush=True)
# Calculate timing metrics
end_time = time.time()
total_time = end_time - start_time
# Calculate tokens per second
if prompt_tokens > 0:
prompt_tps = prompt_tokens / total_time
else:
prompt_tps = 0
if generated_tokens > 0:
generation_tps = generated_tokens / total_time
else:
generation_tps = 0
# Print metrics similar to the screenshot
print("\n\n--- Performance Metrics ---")
print(f"Prompt: {prompt_tokens} tokens, {prompt_tps:.3f} tokens-per-sec")
print(f"Generation: {generated_tokens} tokens, {generation_tps:.3f} tokens-per-sec")
print(f"Total time: {total_time:.2f} seconds")
print(f"Full response length: {len(full_response)} characters")
输出:
该网页是为一家名为“NexaGrowth”的数字营销机构设计的,采用了现代、简洁的设计风格,并精心选择了色调。该网页的布局是响应式的,采用了现代网页设计技术。
您可以在这里查看网站。
点击此处查看完整代码和输出。
旧版更新的背景
为了说明新内容,这里简要回顾一下 3 月 24 日更新前的 V3 基准:
- 首次发布:DeepSeek V3 推出时有 671B 个参数,使用 266.4M H800 GPU 小时对 14.8T 代币进行训练,价格为 550-58 万美元。它引入了多头潜意识(MLA)、多令牌预测(MTP)和无辅助损失负载均衡,实现了 60 令牌/秒的速度,性能超过了 Llama 3.1 405B。
- 训练后:DeepSeek R1 的推理能力被提炼到 V3 中,通过监督微调 (SFT) 和强化学习 (RL) 增强了其性能,只需额外 0.124M GPU 小时即可完成。
- 三月份的更新是在此基础上进行的,重点是可用性和有针对性的性能调整,而不是全面革新。
小结
DeepSeek V3 0324 更新看似很小,却带来了很大的改进。它现在更快了,可以快速处理数学和编码等任务。它还非常稳定,不管是编码还是解决问题,每次都能给出好结果。此外,它还能写 700 行代码而不会出错,这对于用代码构建东西的人来说非常棒。它仍然使用智能的 671B 参数设置,而且价格便宜。请试用新版 DeepSeek V3 0324,并在评论中告诉我您的想法!
免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。











暂无评论内容