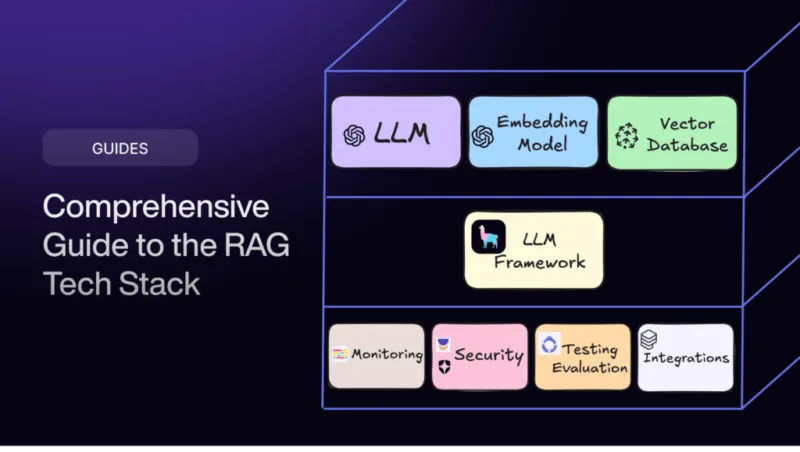
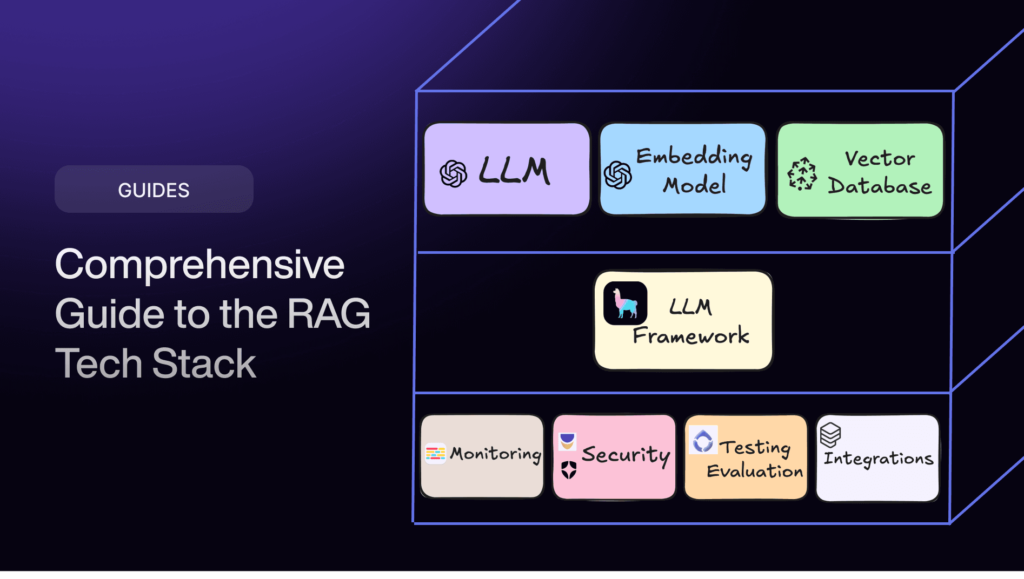
构建 RAG(检索增强生成)应用程序不仅仅是插入几个工具,而是要选择正确的技术堆栈,使检索和生成不仅成为可能,而且高效、可扩展。
比方说,您正在开发类似“基于 PDF 文档的 AI 聊天”的人工智能应用程序,让用户与 PDF 进行对话式交互。这并不像加载文件和提问那么简单。您需要
- 从 PDF 中提取相关内容
- 将文本分割成有意义的片段
- 将这些片段存储到矢量数据库中
- 然后,当用户提出问题时,应用程序会运行相似性搜索,获取最相关的文本块,并将它们传递给语言模型,以生成连贯、准确的回复。
听起来很复杂?是的。跨多个工具、框架和数据库工作会很快让人应接不暇。
这正是整理这份RAG开发技术堆栈的原因–这是一套精心设计的工具和框架,旨在简化整个流程。从智能数据提取器到高效的矢量数据库,再到高性价比的生成模型,它能满足您的一切需求,让您无需每次都重新发明轮子,就能构建强大、可投入生产的 RAG 应用程序。
为什么需要RAG开发堆栈?
Source: Hugging Face
首先,这里简要介绍一下检索增强生成(RAG)–检索增强生成(RAG)通过整合外部信息检索机制来增强大型语言模型(LLMs)的能力。这种方法通过用最新的或特定领域的信息补充静态训练数据,使 LLM 生成更准确、与上下文相关和有事实根据的反应。
RAG如何工作?
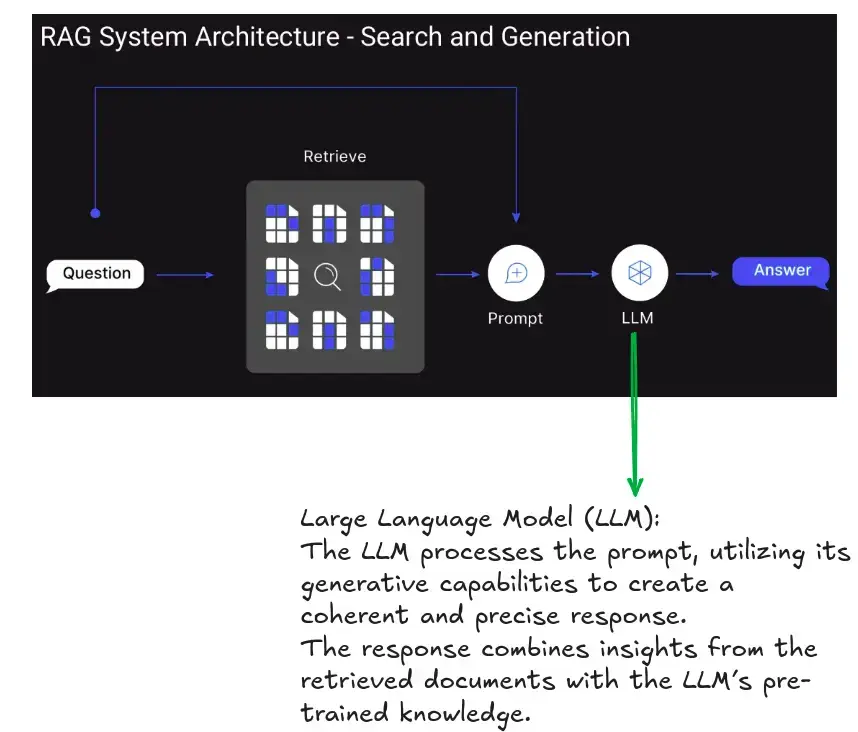
RAG 的运行分为四个关键阶段:
- 编制索引:将外部来源(如文档、数据库)的数据转换为矢量表示(嵌入)并存储在矢量数据库中。这样就能高效检索相关信息。
- 检索:当用户提交查询时,系统会使用基于相似性的搜索技术从索引来源中检索最相关的数据。
- 增强(Augmentation):通过提示工程将检索到的信息与用户的查询结合起来,有效地 “增强” LLM 的输入。
- 生成:LLM 利用其内部知识和增强的提示来生成回复。这一过程可确保输出结果既参考了预先训练的数据,也参考了实时的权威来源。
现在,您为什么需要 RAG 开发堆栈?
为什么需要RAG开发堆栈?
- 加速开发:利用预构建、可随时集成的组件,更快地从原型转向生产。
- 提高准确性:检索实时的、与上下文相关的数据,以确定响应并减少幻觉。
- 加强部署:内置工具增强了安全性、可观察性和可扩展性,使生产准备工作更加顺利。
- 灵活性最大化:模块化设计可让您混合和搭配工具,以适应不同行业和用例的独特需求。
- 可定制设计:开发人员可以根据自己的工作流程、架构和性能目标,亲自挑选适合自己的组件。
为您的下一个项目提供RAG开发堆栈
以下是开发 RAG 项目应了解的 9 件事:
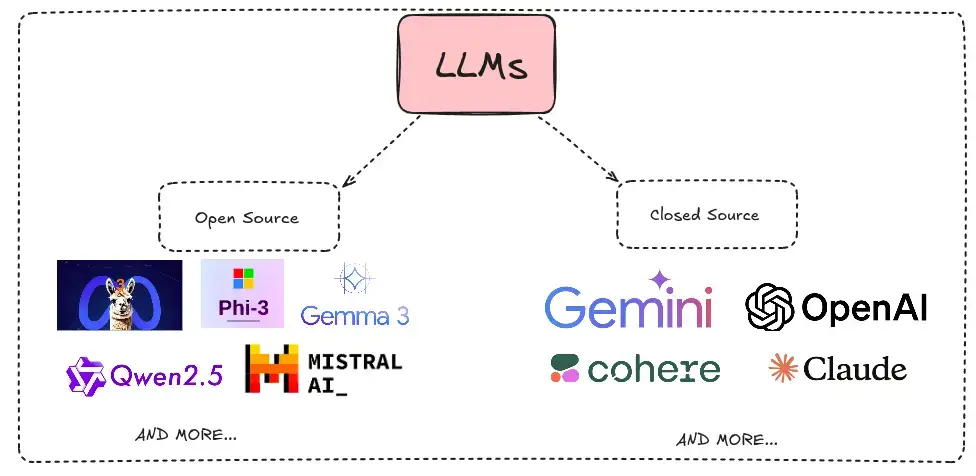
1. 大型语言模型 (LLM)
Source: Author
LLM 是 RAG 系统的大脑,利用基于转换器的架构生成连贯且与上下文相关的文本。这些模型分为两类:
- 开源 LLM:例如 LLaMA、Falcon、Cohere 等,允许定制和本地部署。
- 封源 LLM:GPT-4 和 Bard 等专有模型可提供高级功能,但通常只能通过 API 访问。
Source: Author
在RAG中使用LLM的示例
我已经使用 JSON 加载器导入了 JSON 文档,下面是了解 RAG 中如何使用 LLM 的管道。
提示模板
from langchain_core.prompts import ChatPromptTemplate
rag_prompt = """You are an assistant who is an expert in question-answering tasks.
Answer the following question using only the following pieces of retrieved context.
If the answer is not in the context, do not make up answers, just say that you don't know.
Keep the answer detailed and well formatted based on the information from the context.
Question:
{question}
Context:
{context}
Answer:
"""
rag_prompt_template = ChatPromptTemplate.from_template(rag_prompt)
管道构建
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI
# Initialize ChatGPT model
chatgpt = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# Format documents into a single string
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Construct the RAG pipeline
qa_rag_chain = (
{
"context": (similarity_retriever | format_docs),
"question": RunnablePassthrough()
}
|
rag_prompt_template
|
chatgpt
)
使用示例
query = "What is the difference between AI, ML, and DL?" result = qa_rag_chain.invoke(query) # Display the generated answer from IPython.display import display, Markdown display(Markdown(result.content))
输出

2. 用于RAG响应生成的LLM
在检索增强生成(RAG)系统中,响应生成 LLM 作为最终决策者扮演着重要角色–它将检索到的文档、用户查询和上下文综合成一个连贯的、相关的、通常是对话式的响应。虽然检索模型会带来潜在的有用信息,但 LLM 可以进行推理、总结和上下文关联,从而确保输出结果具有智能感和人性化。这一点在企业搜索、客户支持、法律/医疗助理和技术问答等应用中尤为重要,因为在这些应用中,用户希望得到精确、有根据和可信的回答。
一言以蔽之,如果没有有效的生成模型,即使是最好的检索堆栈也会变得平淡无奇–这使得该组件成为任何 RAG 管道的核心大脑。
商业LLM
| 模型 | 开发商 | 关键优势 | 常见用例 |
|---|---|---|---|
| GPT-4.5 | OpenAI | 高级文本生成、摘要、对话流畅性 | 聊天机器人、客户支持、内容创建 |
| Claude 3.7 Sonnet | Anthropic | 实时对话、强推理、”扩展思维模式” | 业务自动化、客户服务 |
| Gemini 2.0 Pro | Google DeepMind | 多模态(文本 + 图像)、高性能 | 数据分析、企业自动化、内容生成 |
| Cohere Command R+ | Cohere | 检索增强生成(RAG)、企业级设计 | 知识管理、支持自动化、节制 |
| DeepSeek | 深度求索 | 内部部署、安全数据处理、高度可定制性 | 金融、医疗保健、隐私敏感行业 |
开源LLM
| 模型 | 开发商 | 关键优势 | 常见用例 |
|---|---|---|---|
| LLaMA 3 | Meta | 可扩展(多达 405B 个参数)、多模态功能 | 对话式人工智能、研究、内容生成 |
| Mistral 7B | Mistral AI | 轻量级但功能强大,针对代码和聊天进行了优化 | 代码生成、聊天机器人、内容自动化 |
| Falcon 180B | Technology Innovation Institute | 高效、高性能、开放访问 | 实时应用、科学/研究机器人 |
| DeepSeek R1 | 深度求索 | 强大的逻辑/推理能力,128K 上下文窗口 | 数学任务、总结、复杂推理 |
| Qwen2.5-72B-Instruct | 阿里云 | 727 亿个参数,支持多达 128K 标记的长上下文、编码、数学推理和多语言支持。 | 可生成 JSON 等结构化输出,因此在 RAG 工作流程中的技术应用方面具有很强的通用性。 |
3. 框架
Source: Author
框架通过提供预置组件简化了 RAG 应用程序的开发:
- LangChain:用于 LLM 应用程序开发的框架,具有提示管理、链、内存处理和代理创建的模块化架构。擅长构建 RAG 管道,内置支持文档加载器、检索器和向量存储。
- LlamaIndex:用于数据索引和检索的专用框架,通过自定义索引将非结构化数据与语言模型连接起来。针对聊天机器人和知识管理的大型数据集的摄取、转换和查询进行了优化。
- LangGraph:它将 LLM 与基于图的结构集成在一起,允许开发人员使用节点和边定义应用逻辑。它是具有多个分支和反馈回路的复杂工作流的理想选择,尤其适用于多代理系统。
- RAGFlow:专门用于检索-增强生成系统的框架,可将检索器、排序器和生成器协调成连贯的管道。当从外部数据源提取数据用于搜索驱动界面和问答系统时,可增强相关性。
Source: Author
LangChain、LangGraph 和 LlamaIndex 等框架通过提供集成检索和生成流程的模块化工具,大大简化了 RAG(检索-增强生成)的开发。LangChain 简化了 LLM 调用链、提示管理以及与向量存储的连接。LangGraph 引入了基于图形的流程控制,实现了动态和多步骤的 RAG 工作流。LlamaIndex 专注于数据摄取、索引和检索,使 LLM 可以查询大型数据集。它们共同抽象出复杂的基础架构,使开发人员能够专注于逻辑和数据质量。通过这些工具,可以为问题解答、文档搜索和知识辅助等任务快速创建原型并稳健部署 RAG 应用程序。
构建RAG的框架示例
让我们使用 LangChain 构建一个简单的 RAG:
%pip install --quiet --upgrade langchain-text-splitters langchain-community langgraph !pip install -qU "langchain[openai]"
聊天模型
import getpass
import os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter API key for OpenAI: ")
from langchain.chat_models import init_chat_model
llm = init_chat_model("gpt-4o-mini", model_provider="openai")
选择嵌入模型
from langchain_openai import OpenAIEmbeddings embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
选择矢量存储
from langchain_core.vectorstores import InMemoryVectorStore vector_store = InMemoryVectorStore(embeddings)
创建索引管道
import bs4
from langchain import hub
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langgraph.graph import START, StateGraph
from typing_extensions import List, TypedDict
# Load and chunk contents of the blog
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
all_splits = text_splitter.split_documents(docs)
# Index chunks
_ = vector_store.add_documents(documents=all_splits)
# Define prompt for question-answering
prompt = hub.pull("rlm/rag-prompt")
# Define state for application
class State(TypedDict):
question: str
context: List[Document]
answer: str
# Define application steps
def retrieve(state: State):
retrieved_docs = vector_store.similarity_search(state["question"])
return {"context": retrieved_docs}
def generate(state: State):
docs_content = "\n\n".join(doc.page_content for doc in state["context"])
messages = prompt.invoke({"question": state["question"], "context": docs_content})
response = llm.invoke(messages)
return {"answer": response.content}
# Compile application and test
graph_builder = StateGraph(State).add_sequence([retrieve, generate])
graph_builder.add_edge(START, "retrieve")
graph = graph_builder.compile()
response = graph.invoke({"question": "What are Types of Memory?"})
print(response["answer"])
输出
The types of memory include Sensory Memory, Short-Term Memory (STM), and Long-Term Memory (LTM). Sensory Memory retains impressions of sensory information for a few seconds, while Short-Term Memory holds currently relevant information for 20-30 seconds. Long-Term Memory can store information for days to decades and includes explicit (declarative) and implicit (procedural) memory.
4. 数据提取
Source: Author
如果要从其他来源提取数据,那么数据提取工具就能很好地发挥作用。RAG 应用程序需要强大的工具来从各种来源提取结构化和非结构化数据:
- 网站、PDF、Word 文档、幻灯片等。
- BeautifulSoup 或 PyPDF2 等工具可以自动完成这一过程。
用于构建RAG的数据提取示例
pip install -U langchain-community %pip install langchain pypdf
让我们从PDF文件中提取内容
# %pip install langchain pypdf
from langchain.document_loaders import PyPDFLoader
# Define the path to your PDF file
pdf_path = "/content/Multimodal Agent Using Agno Framework.pdf"
# Initialize the PyPDFLoader
loader = PyPDFLoader(pdf_path)
# Load the PDF and split it into pages
documents = loader.load()
# Print the content of each page
for i, doc in enumerate(documents):
print(f"Page {i + 1} Content:")
print(doc.page_content)
print("\n")
输出

5. 嵌入器
Source: Author
文本嵌入将文本数据转化为数字向量,用于基于相似性的检索。超越文本嵌入:
- 图像嵌入:用于多模态 RAG 应用。
- 多模态嵌入:结合文本、图像和其他数据类型来完成复杂的任务。
以下是各提供商的嵌入模型:
OpenAI嵌入模型
- 最新模型:text-embedding-3-small (成本较低)和 text-embedding-3-large(准确度较高)
- 功能: 动态维度调整(如 256-3072 dim)、多语言支持、针对搜索/RAG 进行了优化
Cohere Embed v3
- 专注于文档质量排名和噪声数据处理
- 模型: 英语/多语种变体(1024/384 dim),压缩感知训练以提高成本效益
Nomic Embed v2
- 具有 Matryoshka 嵌入的开源 MoE 架构(3.05 亿个活动参数)
- 多语种(100 多种语言),在 MTEB/BEIR 基准测试中表现优于 2 倍规模的模型
Gemini嵌入
- 具有 8K 标记输入和 3K 维度的实验模型(gemini-embedding-exp-03-07)
- MTEB 排行榜领先者(平均分 68.32),支持 100 多种语言
Ollama嵌入
- 支持 mxbai-embed-large 等模型和自定义变体(如 suntray-embedding)。
- 专为 RAG 工作流设计,具有本地推理和 ChromaDB 集成功能
BGE (BAAI)
- 基于 BERT 的模型(大型/基础/小型-en-v1.5),用于检索/RAG
- 开源,支持指令调整(例如 “表示这个句子……”)
Mixedbread
- Mixedbread AI 的 mxbai-embed-large-v1 模型是最先进的句子嵌入解决方案,专为多语言和多模态检索任务而设计。
- 它支持 Matryoshka 表征学习(MRL)和二进制量化等先进技术,可实现高效内存使用和大规模降低成本。它在各种任务中表现出色,可与大型专有模型相媲美,同时保持开源的可访问性。
将PDF内容分割成块
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def create_simple_chunks(file_path, chunk_size=3500, chunk_overlap=200):
loader = PyMuPDFLoader(file_path)
doc_pages = loader.load()
splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
return splitter.split_documents(doc_pages)
from glob import glob
pdf_files = glob('./rag_docs/*.pdf')
# Process PDF files
paper_docs = []
for fp in pdf_files:
paper_docs.extend(create_simple_chunks(file_path=fp))
输出
Loading pages: ./rag_docs/cnn_paper.pdfChunking pages: ./rag_docs/cnn_paper.pdfFinished processing: ./rag_docs/cnn_paper.pdfLoading pages: ./rag_docs/attention_paper.pdfChunking pages: ./rag_docs/attention_paper.pdfFinished processing: ./rag_docs/attention_paper.pdfLoading pages: ./rag_docs/vision_transformer.pdfChunking pages: ./rag_docs/vision_transformer.pdfFinished processing: ./rag_docs/vision_transformer.pdfLoading pages: ./rag_docs/resnet_paper.pdfChunking pages: ./rag_docs/resnet_paper.pdfFinished processing: ./rag_docs/resnet_paper.pdf
创建嵌入
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
# Initialize embedding model
openai_embed_model = OpenAIEmbeddings(model='text-embedding-3-small')
# Combine documents
total_docs = wiki_docs_processed + paper_docs
# Create and save vector database
chroma_db = Chroma.from_documents(documents=total_docs,
collection_name='my_db',
embedding=openai_embed_model,
collection_metadata={"hnsw:space": "cosine"},
persist_directory="./my_db")
6. 矢量数据库
矢量数据库存储嵌入(文本或其他数据的数字表示),可高效检索语义相似的数据块。例子包括
- Pinecone:一个可管理的矢量数据库平台,专为高性能和可扩展的应用而设计,可实现高维矢量嵌入的高效存储和检索。
- Chroma DB:一个开源的人工智能原生嵌入式数据库,包括矢量搜索、文档存储、全文搜索和元数据过滤等功能,可促进人工智能应用中的无缝检索。
- Qdrant:用 Rust 编写的开源矢量数据库和搜索引擎,提供快速、可扩展的矢量相似性搜索服务,支持扩展过滤,适用于基于神经网络或语义的匹配。
- Milvus DB:为可扩展的相似性搜索而构建的开源矢量数据库,能够处理大规模动态矢量数据,并支持各种索引类型以实现高效检索。
- Weaviate:开源矢量数据库,可同时存储对象和矢量,可将矢量搜索与结构化过滤相结合,具有模块化、云原生和实时性等特点。
用于构建RAG的矢量数据库示例
注:上面我们已经做了嵌入,现在我们将把它们存储到矢量数据库中。
使用Chroma db存储嵌入式数据
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
# Initialize embedding model
openai_embed_model = OpenAIEmbeddings(model='text-embedding-3-small')
# Combine documents
total_docs = wiki_docs_processed + paper_docs
# Create and save vector database
chroma_db = Chroma.from_documents(documents=total_docs,
collection_name='my_db',
embedding=openai_embed_model,
collection_metadata={"hnsw:space": "cosine"},
persist_directory="./my_db")
加载矢量数据库
chroma_db = Chroma(persist_directory="./my_db", collection_name='my_db', embedding_function=openai_embed_model)
检索信息并获得输出
similarity_retriever = chroma_db.as_retriever(search_type="similarity", search_kwargs={"k": 5})
# Query for semantic similarity
query = "What is machine learning?"
top_docs = similarity_retriever.invoke(query)
# Display results
from IPython.display import display, Markdown
def display_docs(docs):
for doc in docs:
print('Metadata:', doc.metadata)
print('Content Brief:')
display(Markdown(doc.page_content[:1000]))
print()
display_docs(top_docs)
输出

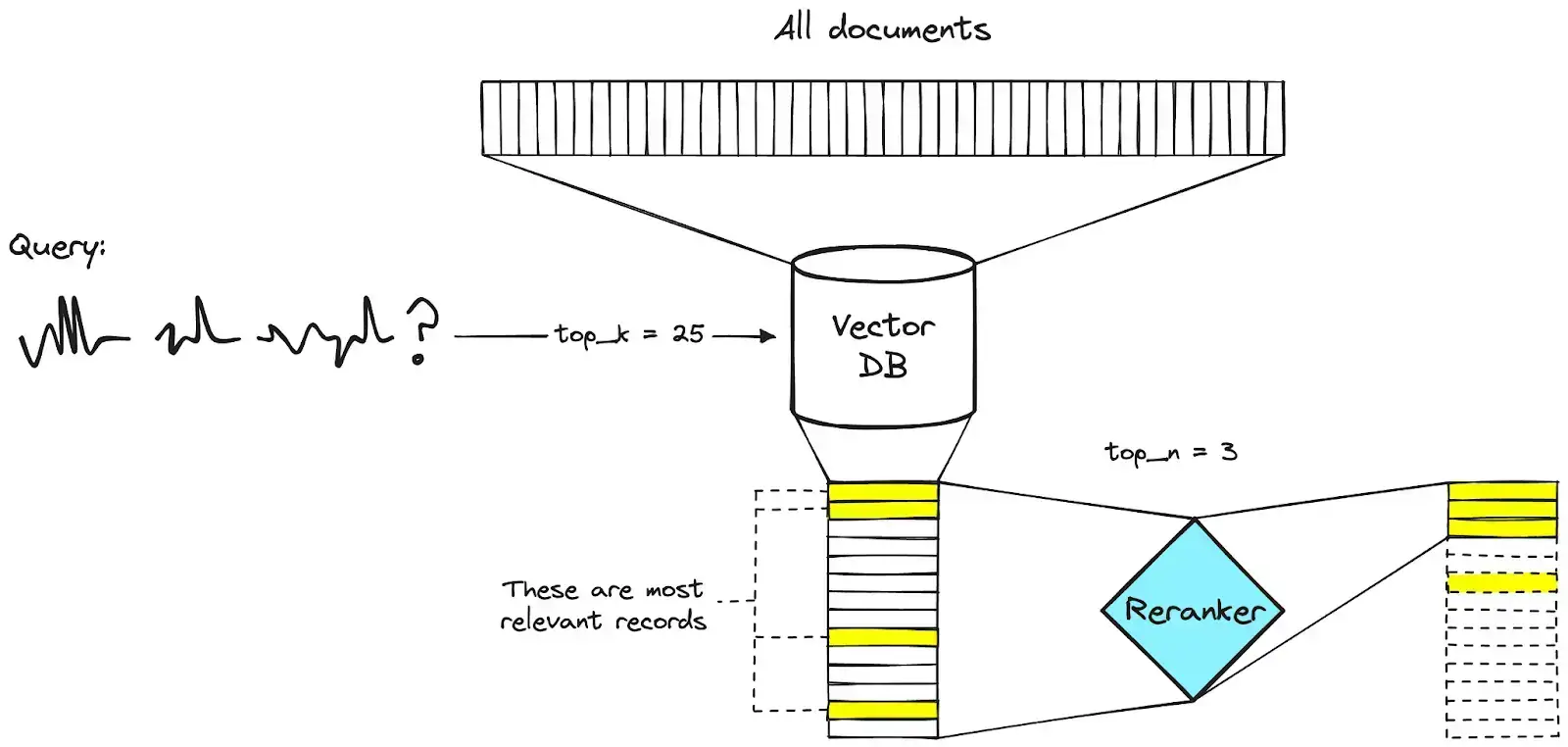
7. 重新排序
Source: Link
重新排序器通过提高检索文档的相关性来完善检索过程:
它们在两个阶段的检索管道中运行:
- 初始检索从向量数据库中检索出大量候选文档。
- 重新排序器会根据语义相似性或上下文相关性等附加评分机制对最相关的文档进行优先排序。
通过将重新排序器集成到堆栈中,开发人员可以确保为用户查询量身定制更高质量的响应,同时优化检索效率。
构建RAG的Reranker示例
%pip install --upgrade --quiet cohere
设置 Cohere 和 ContextualCompressionRetriever
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever from langchain_cohere import CohereRerank from langchain_community.llms import Cohere from langchain.chains import RetrievalQA llm = Cohere(temperature=0) compressor = CohereRerank(model="rerank-english-v3.0") compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=retriever ) chain = RetrievalQA.from_chain_type( llm=Cohere(temperature=0), retriever=compression_retriever )
输出

8. 评估
评估可确保 RAG 系统的准确性和相关性:
- Giskard:用于测试机器学习管道的库。
- Ragas:专门设计用于通过分析检索质量和生成的输出来评估 RAG 管道。
- Arize Phoenix:一个开源的可观测性库,用于评估、故障诊断和改进 LLM 输出,具有模型漂移检测和队列分析等功能。
- Comet Opik:一个完全开源的平台,用于评估、测试和监控 LLM 应用程序,并在整个开发生命周期中提供可观测性、自动评分和单元测试工具。
- DeepEval:deepeval 提供三种 LLM 评估指标来评估检索:
- ContextualPrecisionMetric:评估检索器(retriever)中的重新排序器(reranker)是否将检索上下文中更相关的节点排在比不相关节点更靠前的位置。
- ContextualRecallMetric:评估检索器中的嵌入模型是否能根据输入上下文准确捕捉和检索相关信息。
- ContextualRelevancyMetric:评估检索器的文本块大小和 top-K 是否能够检索到不太相关的信息。
建立RAG的评估示例
from tqdm.notebook import tqdm
from datasets import load_dataset
from qdrant_client import QdrantClient
from tqdm import tqdm
from langchain.docstore.document import Document as LangchainDocument
from langchain_text_splitters import RecursiveCharacterTextSplitter
from openai import OpenAI
import deepeval
# Get your key from https://platform.openai.com/api-keys
OPENAI_API_KEY = ""
# Get your Confident AI API key from https://app.confident-ai.com
CONFIDENT_AI_API_KEY = ""
# Get a FREE forever cluster at https://cloud.qdrant.io/
# More info: https://qdrant.tech/documentation/cloud/create-cluster/
QDRANT_URL = ""
QDRANT_API_KEY = ""
COLLECTION_NAME = "qdrant-deepeval"
EVAL_SIZE = 10
RETRIEVAL_SIZE = 3
dataset = load_dataset("atitaarora/qdrant_doc", split="train")
langchain_docs = [
LangchainDocument(
page_content=doc["text"], metadata={"source": doc["source"]}
)
for doc in tqdm(dataset)
]
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50,
add_start_index=True,
separators=["\n\n", "\n", ".", " ", ""],
)
docs_processed = []
for doc in langchain_docs:
docs_processed += text_splitter.split_documents([doc])
client = QdrantClient(url=QDRANT_URL, api_key=QDRANT_API_KEY)
docs_contents, docs_metadatas = [], []
for doc in docs_processed:
if hasattr(doc, "page_content") and hasattr(doc, "metadata"):
docs_contents.append(doc.page_content)
docs_metadatas.append(doc.metadata)
else:
print(
"Warning: Some documents do not have 'page_content' or 'metadata' attributes."
)
# Uses FastEmbed - https://qdrant.tech/documentation/fastembed/
# To generate embeddings for the documents
# The default model is `BAAI/bge-small-en-v1.5`
client.add(
collection_name=COLLECTION_NAME,
metadata=docs_metadatas,
documents=docs_contents,
)
openai_client = OpenAI(api_key=OPENAI_API_KEY)
def query_with_context(query, limit):
search_result = client.query(
collection_name=COLLECTION_NAME, query_text=query, limit=limit
)
contexts = [
"document: " + r.document + ",source: " + r.metadata["source"]
for r in search_result
]
prompt_start = """ You're assisting a user who has a question based on the documentation.
Your goal is to provide a clear and concise response that addresses their query while referencing relevant information
from the documentation.
Remember to:
Understand the user's question thoroughly.
If the user's query is general (e.g., "hi," "good morning"),
greet them normally and avoid using the context from the documentation.
If the user's query is specific and related to the documentation, locate and extract the pertinent information.
Craft a response that directly addresses the user's query and provides accurate information
referring the relevant source and page from the 'source' field of fetched context from the documentation to support your answer.
Use a friendly and professional tone in your response.
If you cannot find the answer in the provided context, do not pretend to know it.
Instead, respond with "I don't know".
Context:\n"""
prompt_end = f"\n\nQuestion: {query}\nAnswer:"
prompt = prompt_start + "\n\n---\n\n".join(contexts) + prompt_end
res = openai_client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt=prompt,
temperature=0,
max_tokens=636,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
stop=None,
)
return (contexts, res.choices[0].text)
qdrant_qna_dataset = load_dataset("atitaarora/qdrant_doc_qna", split="train")
def create_deepeval_dataset(dataset, eval_size, retrieval_window_size):
test_cases = []
for i in range(eval_size):
entry = dataset[i]
question = entry["question"]
answer = entry["answer"]
context, rag_response = query_with_context(
question, retrieval_window_size
)
test_case = deepeval.test_case.LLMTestCase(
input=question,
actual_output=rag_response,
expected_output=answer,
retrieval_context=context,
)
test_cases.append(test_case)
return test_cases
test_cases = create_deepeval_dataset(
qdrant_qna_dataset, EVAL_SIZE, RETRIEVAL_SIZE
)
deepeval.login_with_confident_api_key(CONFIDENT_AI_API_KEY)
deepeval.evaluate(
test_cases=test_cases,
metrics=[
deepeval.metrics.AnswerRelevancyMetric(),
deepeval.metrics.FaithfulnessMetric(),
deepeval.metrics.ContextualPrecisionMetric(),
deepeval.metrics.ContextualRecallMetric(),
deepeval.metrics.ContextualRelevancyMetric(),
],
)
9. 开放LLM访问
支持本地或基于应用程序接口访问开放式 LLM 的平台包括
- Ollama:允许在本地运行开放式 LLM。
- Groq、Hugging Face、Together AI:为开放式 LLM 提供 API 集成。
用于构建RAG的开放式LLM访问示例
下载 Ollama:点击此处下载
curl -fsSL https://ollama.com/install.sh | sh
之后,使用下面命令提取 DeepSeek R1:1.5b:
ollama pull deepseek-r1:1.5b
安装所需的库
!pip install langchain==0.3.11 !pip install langchain-openai==0.2.12 !pip install langchain-community==0.3.11 !pip install langchain-chroma==0.1.4
开放式AI嵌入模型
from langchain_openai import OpenAIEmbeddings openai_embed_model = OpenAIEmbeddings(model='text-embedding-3-small')
创建矢量数据库并在磁盘上持久化
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader('AgenticAI.pdf')
pages = loader.load_and_split()
texts = [doc.page_content for doc in pages]
from langchain_chroma import Chroma
chroma_db = Chroma.from_texts(
texts=texts,
collection_name='db_docs',
collection_metadata={"hnsw:space": "cosine"}, # Set distance function to cosine
embedding=openai_embed_model
)
构建RAG链
from langchain_core.prompts import ChatPromptTemplate
prompt = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If no context is present or if you don't know the answer, just say that you don't know.
Do not make up the answer unless it is there in the provided context.
Keep the answer concise and to the point with regard to the question.
Question:
{question}
Context:
{context}
Answer:
"""
prompt_template = ChatPromptTemplate.from_template(prompt)
加载与LLM的连接
from langchain_community.llms import Ollama deepseek = Ollama(model="deepseek-r1:1.5b")
用于RAG链的LangChain语法
from langchain.chains import Retrieval
rag_chain = Retrieval.from_chain_type(llm=deepseek,
chain_type="stuff",
retriever=similarity_threshold_retriever,
chain_type_kwargs={"prompt": prompt_template})
query = "Tell the Leaders’ Perspectives on Agentic AI"
rag_chain.invoke(query)
{'query': 'Tell the Leaders’ Perspectives on Agentic AI',
输出

小结
构建有效的 RAG 应用程序并不仅仅是插入一个语言模型,而是要选择正确的 RAG 开发人员堆栈,从框架和嵌入到向量数据库和检索工具。当这些组件经过深思熟虑的整合后,就能实现智能、可扩展的系统,这些系统可以与 PDF 聊天,实时提取相关事实,并生成上下文感知响应。随着生态系统的不断发展,保持工具的灵活性和坚实的架构基础将是构建可靠、面向未来的人工智能解决方案的关键。
免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。












暂无评论内容