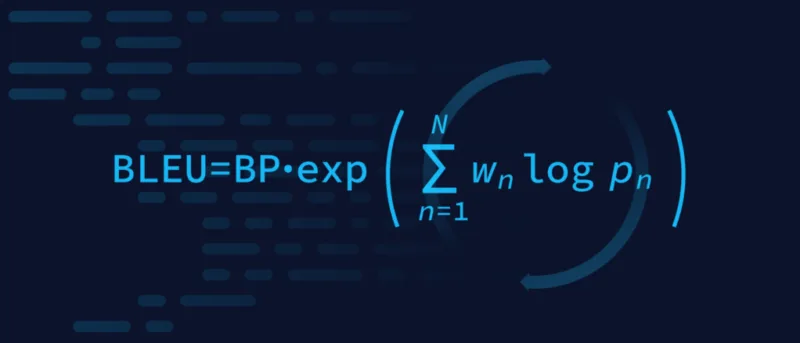
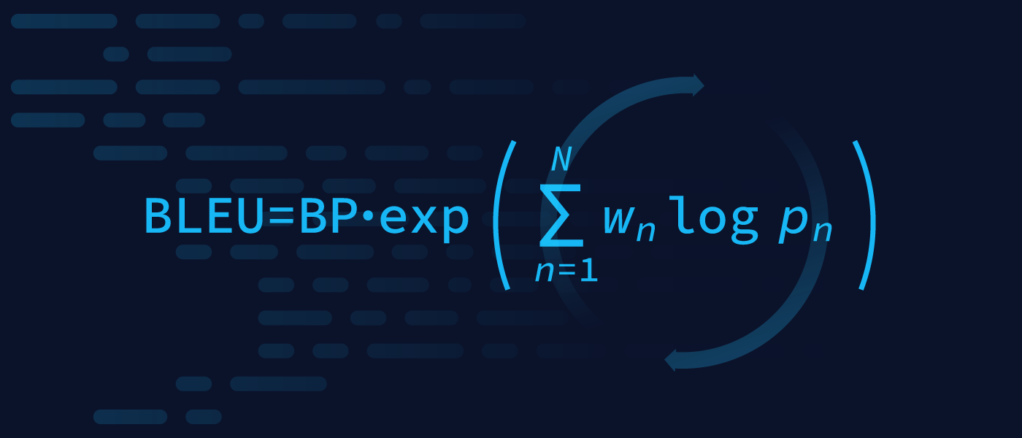
在人工智能领域,评估语言模型的性能是一项独特的挑战。与图像识别或数字预测不同,语言质量评估并不局限于简单的二进制测量。BLEU(Bilingual Evaluation Understudy)自 2002 年由 IBM 研究人员引入以来,已成为机器翻译评估的基石。
BLEU 是自然语言处理领域的一项突破,因为它是第一种既能与人类判断达到相当高的相关性,又能保持自动化效率的评估方法。本文将探讨 BLEU 的机制、应用、局限性,以及在人工智能日益驱动、关注语言生成输出中更多细微差别的世界中,BLEU 的前景如何。
BLEU指标的起源:历史视角
在 BLEU 出现之前,机器翻译的评估主要依靠人工–这是一个资源密集型过程,需要语言专家对每项输出进行人工评估。IBM Research 的 Kishore Papineni、Salim Roukos、Todd Ward 和 Wei-Jing Zhu 引入 BLEU 代表着一种模式的转变。他们在 2002 年发表的论文 “BLEU:一种机器翻译自动评估方法 ”中提出了一种自动度量方法,该方法可以对翻译进行评分,并与人类的判断非常一致。
时机非常关键。随着统计机器翻译系统的发展,该领域迫切需要标准化的评估方法。BLEU 填补了这一空白,提供了一种可重复的、与语言无关的评分机制,有助于对不同翻译系统进行有意义的比较。
BLEU指标如何工作?
BLEU 的核心原理很简单:将机器生成的译文与参考译文(通常由人工翻译人员创建)进行比较。据观察,BLEU 分数会随着句子长度的增加而降低,但可能会因翻译模型的不同而有所变化。不过,其实现涉及复杂的计算语言学概念:
N-gram 精确度
BLEU 的基础在于 N-gram 精确度–机器翻译中出现在任何参考译文中的词序列的百分比。BLEU 不局限于单个单词(unigrams),而是检查不同长度的连续序列:
- 单字(单词)修正精度:衡量词汇准确性
- 大词(双词序列)修正精度:捕捉基本短语的正确性
- 三词组和四词组修正精度:评估语法结构和词序
BLEU 通过以下方法计算每个 n-gram 长度的修正精度:
- 计算候选译文和参考译文之间的 n-gram 匹配度
- 应用 “剪切 ”机制以防止重复词的过度膨胀
- 除以候选译文中的 n-gram 总数
简洁度惩罚
为防止系统通过编写极短的译文(只包含容易匹配的词即可达到高精确度)来玩弄该指标,BLEU 加入了简短度惩罚,以降低比参考译文短的译文的得分。
该惩罚的计算公式为
BP = exp(1 - r/c) if c < r 1 if c ≥ r
其中,r 是参考长度,c 是候选翻译长度。
最终BLEU得分
最终的 BLEU 得分是将这些组成部分合并为一个介于 0 和 1 之间的单一值(通常以百分比表示):
BLEU = BP × exp(∑ wn log pn)
其中
- BP 是简洁性惩罚
- wn 表示每个 n-gram 精确度的权重(通常为统一权重)
- pn 是长度为 n 的 n 字节的修正精度
实施BLEU指标
从概念上理解 BLEU 是一回事,正确实施 BLEU 则需要关注细节。以下是有效使用 BLEU 的实用指南:
所需输入
BLEU 需要两个主要输入:
- 候选翻译:要评估的机器生成的译文
- 参考译文:每个源句的一个或多个人工生成的译文
这两个输入必须经过一致的预处理:
- 标记化:将文本分解为单词或子单词
- 大小写规范化:通常将所有文本的大小写降为小写
- 标点符号处理:移除标点符号或将标点符号作为单独标记符处理
实现步骤
典型的 BLEU 实现步骤如下:
- 预处理所有翻译 : 应用一致的标记化和规范化
- 计算 n=1 到 N 的 n-gram 精确度(通常 N=4):
- 计算候选翻译中的所有 n-grams
- 计算参考译文中的匹配 n-格(带剪裁)
- 计算精确度为(匹配/候选 n-gram 总数)
- 计算简短度惩罚 :
- 确定有效参考长度(原始 BLEU 中最短的参考长度)
- 与候选长度相比
- 应用简短度惩罚公式
- 将各部分合并为最终得分:
- 应用 n-gram 精确度的加权几何平均数
- 乘以简短度惩罚
常用实现工具
有几个库提供了即用型 BLEU 实现:
NLTK:Python的自然语言工具包提供了简单的BLEU实现
from nltk.translate.bleu_score import sentence_bleu, corpus_bleu
from nltk.translate.bleu_score import SmoothingFunction
# Create a smoothing function to avoid zero scores due to missing n-grams
smoothie = SmoothingFunction().method1
# Example 1: Single reference, good match
reference = [['this', 'is', 'a', 'test']]
candidate = ['this', 'is', 'a', 'test']
score = sentence_bleu(reference, candidate)
print(f"Perfect match BLEU score: {score}")
# Example 2: Single reference, partial match
reference = [['this', 'is', 'a', 'test']]
candidate = ['this', 'is', 'test']
# Using smoothing to avoid zero scores
score = sentence_bleu(reference, candidate, smoothing_function=smoothie)
print(f"Partial match BLEU score: {score}")
# Example 3: Multiple references (corrected format)
references = [[['this', 'is', 'a', 'test']], [['this', 'is', 'an', 'evaluation']]]
candidates = [['this', 'is', 'an', 'assessment']]
# The format for corpus_bleu is different - references need restructuring
correct_references = [[['this', 'is', 'a', 'test'], ['this', 'is', 'an', 'evaluation']]]
score = corpus_bleu(correct_references, candidates, smoothing_function=smoothie)
print(f"Multiple reference BLEU score: {score}")
输出
Perfect match BLEU score: 1.0Partial match BLEU score: 0.19053627645285995Multiple reference BLEU score: 0.3976353643835253
SacreBLEU:解决可重复性问题的标准化BLEU实现
import sacrebleu
# For sentence-level BLEU with SacreBLEU
reference = ["this is a test"] # List containing a single reference
candidate = "this is a test" # String containing the hypothesis
score = sacrebleu.sentence_bleu(candidate, reference)
print(f"Perfect match SacreBLEU score: {score}")
# Partial match example
reference = ["this is a test"]
candidate = "this is test"
score = sacrebleu.sentence_bleu(candidate, reference)
print(f"Partial match SacreBLEU score: {score}")
# Multiple references example
references = ["this is a test", "this is a quiz"] # List of multiple references
candidate = "this is an exam"
score = sacrebleu.sentence_bleu(candidate, references)
print(f"Multiple references SacreBLEU score: {score}")
输出
Perfect match SacreBLEU score: BLEU = 100.00 100.0/100.0/100.0/100.0 (BP = 1.000 ratio = 1.000 hyp_len = 4 ref_len = 4)Partial match SacreBLEU score: BLEU = 45.14 100.0/50.0/50.0/0.0 (BP = 0.717 ratio = 0.750 hyp_len = 3 ref_len = 4)Multiple references SacreBLEU score: BLEU = 31.95 50.0/33.3/25.0/25.0 (BP = 1.000 ratio = 1.000 hyp_len = 4 ref_len = 4)
Hugging Face评估:与ML管道集成的现代实现
from evaluate import load
bleu = load('bleu')
# Example 1: Perfect match
predictions = ["this is a test"]
references = [["this is a test"]]
results = bleu.compute(predictions=predictions, references=references)
print(f"Perfect match HF Evaluate BLEU score: {results}")
# Example 2: Multi-sentence evaluation
predictions = ["the cat is on the mat", "there is a dog in the park"]
references = [["the cat sits on the mat"], ["a dog is running in the park"]]
results = bleu.compute(predictions=predictions, references=references)
print(f"Multi-sentence HF Evaluate BLEU score: {results}")
# Example 3: More complex real-world translations
predictions = ["The agreement on the European Economic Area was signed in August 1992."]
references = [["The agreement on the European Economic Area was signed in August 1992.", "An agreement on the European Economic Area was signed in August of 1992."]]
results = bleu.compute(predictions=predictions, references=references)
print(f"Complex example HF Evaluate BLEU score: {results}")
输出
Perfect match HF Evaluate BLEU score: {'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 4, 'reference_length': 4}Multi-sentence HF Evaluate BLEU score: {'bleu': 0.0, 'precisions': [0.8461538461538461, 0.5454545454545454, 0.2222222222222222, 0.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 13, 'reference_length': 13}Complex example HF Evaluate BLEU score: {'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 13, 'reference_length': 13}
解读BLEU输出
BLEU 分数的范围通常为 0 到 1(如果以百分比表示,则为 0 到 100):
- 0:候选者与参考文献之间不匹配
- 1(或 100%):与参考文献完全匹配
- 典型范围 :
- 0-15: 翻译不佳
- 15-30: 可以理解,但翻译有缺陷
- 30-40: 翻译良好
- 40-50: 高质量翻译
- 50+: 优秀翻译(可能接近人类质量)
然而,这些范围在不同语对之间存在很大差异。例如,英汉之间的翻译得分通常低于英法之间的翻译,这是语言差异造成的,而非实际质量差异。
得分差异
不同的 BLEU 实现可能会产生不同的分数,原因如下
- 平滑方法:处理零精度值
- 标记化差异:对于没有明确词界的语言尤其重要
- N-gram 加权方案:标准 BLEU 使用统一权重,但也有替代方案
更多信息,请观看此视频:
超越翻译:BLEU的扩展应用
虽然 BLEU 是为机器翻译评估而设计的,但其影响已扩展到整个自然语言处理领域:
- 文本摘要 – 研究人员已将 BLEU 用于评估自动摘要系统,将模型生成的摘要与人工创建的参考文献进行比较。虽然总结带来了独特的挑战,例如需要保留语义而不是准确的措辞,但经修改的 BLEU 变体已被证明在这一领域很有价值。
- 对话系统和聊天机器人 – 对话式 人工智能开发人员使用 BLEU 来衡量对话系统的响应质量,但有一些重要的注意事项。对话的开放性意味着多个回复可能同样有效,这使得基于参考的评估尤其具有挑战性。不过,BLEU 为评估回复的适当性提供了一个起点。
- 图像字幕 – 在多模态人工智能中,BLEU 可帮助评估生成图像文本描述的系统。通过将模型生成的标题与人类注释进行比较,研究人员可以量化标题的准确性,同时承认描述的创造性。
- 代码生成 – 一种新兴的应用涉及评估代码生成模型,BLEU 可以测量人工智能生成的代码与参考实现之间的相似性。这一应用凸显了 BLEU 在不同类型结构化语言中的通用性。
局限性:为什么BLEU并不完美?
尽管 BLEU 被广泛采用,但它也有研究人员必须考虑的有据可查的局限性:
- 语义盲区 – BLEU 最大的局限可能是无法捕捉语义等同性。两个译文可以用完全不同的词表达相同的意思,但 BLEU 会给与参考词性不匹配的变体打低分。这种 “表层 ”评价可能会损害有效的文体选择和替代措辞。
- 缺乏语境理解 – BLEU 将句子视为孤立的单元,忽略了文档层面的连贯性和语境的适当性。在评估上下文对选词和含义有重大影响的文本翻译时,这种局限性尤其容易产生问题。
- 对关键错误不敏感 – 并非所有翻译错误都具有同等权重。一个微小的词序差异可能几乎不影响可理解性,而一个翻译错误的否定则可能扭转整个句子的意思。BLEU 对这些错误一视同仁,无法区分微不足道的错误和关键性错误。
- 参考依赖性 – BLEU 对参考译文的依赖带来了固有的偏见。该指标无法识别与提供的参考译文有显著差异的有效译文的优劣。这种依赖性也给低资源语言带来了实际挑战,因为在低资源语言中很难获得多个高质量的参考译文。
超越BLEU:评估指标的演变
BLEU 的局限性促进了补充性指标的发展,每种指标都能解决特定的缺陷:
- METEOR(使用显式构词法评估翻译的度量标准)- METEOR 通过以下方式加强评估:
- 词干和同义词匹配以识别语义等同性
- 明确的词序评估
- 精确度和召回率的参数化加权
- chrF(字符 n-gram F-score)- 该指标在字符层面而非单词层面运行,因此对于词形丰富的语言特别有效,因为在这些语言中,单词的细微变化可能会大量出现。
- BERTScore – 利用 BERT 等转换器模型的上下文嵌入,该指标可捕捉译文和参考文献之间的语义相似性,解决 BLEU 的语义盲点问题。
- COMET(跨语言优化翻译评估指标)- COMET 使用根据人类判断训练的神经网络来预测翻译质量,有可能捕捉到与人类感知相关但传统指标无法捕捉到的翻译方面。
神经机器翻译时代BLEU的未来
随着神经机器翻译系统越来越多地生成人类质量的输出结果,BLEU 面临着新的挑战和机遇:
- 天花板效应 – 在某些语言对上,表现最好的 NMT 系统现在的 BLEU 分数已经接近或超过了人工翻译。这种 “天花板效应 ”让人怀疑 BLEU 在区分高绩效系统方面是否仍然有用。
- 人类平等的争论 – 最近机器翻译中“人类平等”的说法引发了关于评估方法的争论。BLEU 已成为这些讨论的核心,研究人员质疑当前的指标是否能充分反映接近人类水平的翻译质量。
- 领域定制 – 不同领域对翻译质量的优先级不同。医学翻译要求术语精确,而市场营销内容可能更看重创造性的改编。未来的 BLEU 实现可能会纳入特定领域的权重,以反映这些不同的优先级。
- 与人工反馈相结合 – 最有前途的方向可能是将 BLEU 等自动化指标与有针对性的人工评估相结合的混合评估方法。这些方法可以利用 BLEU 的效率,同时通过战略性的人工干预来弥补其盲点。
小结
尽管 BLEU 有其局限性,但它仍然是机器翻译研究和开发的基础。它的简单性、可重复性以及与人类判断的相关性使其成为翻译评估的通用语言。虽然更新的度量标准解决了 BLEU 的特定弱点,但还没有一个能完全取代它。
BLEU 的故事反映了人工智能领域更广泛的模式:计算效率与细致评估之间的矛盾。随着语言技术的进步,我们的评估方法也必须同步发展。BLEU 的最大贡献可能最终会成为建立更复杂评估范式的基础。
随着机器人成为人类交流的中介,BLEU 等指标已不仅仅是一种研究行为,而是确保人工智能驱动的语言工具满足人类需求的保障。了解 BLEU 指标的所有优点和局限性,对于任何从事技术与语言结合工作的人来说都是不可或缺的。
免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。












暂无评论内容