

想象一下,假设您是在与真人聊天,那么您可以在网上随意聊天。但如果不是呢?如果屏幕后面是一个经过训练听起来像人的人工智能模型呢?在最近 2025 年的一项研究中,来自加州大学圣地亚哥分校的研究人员发现,像 GPT-4.5 这样的大型语言模型可以令人信服地冒充人类,有时甚至比真人还像。通过使用更新版的图灵测试,他们发现这些模型不仅能回答问题,还能模仿人类的不完美之处。在本文章中,我们将探讨人工智能如何跨越工具与社会存在之间的界限,以及这对我们意味着什么。
什么是图灵测试?
图灵测试(或称“模仿游戏”)由艾伦-图灵于 1950 年提出,旨在回答这样一个问题:机器会思考吗?机器会思考吗?在这个测试中,图灵提供了一个实用的测试方法:如果一台机器能够以人类法官无法将其与另一台机器可靠地区分开来的方式进行对话,那么这台机器就可以说是能够 “思考 ”的。
图灵测试仍然具有现实意义,因为它迫使我们面对法学硕士时代的一个基本问题: 机器能否在社会中与人无异?如果一个语言模型能够很好地模仿我们说话、推理和表达的方式,甚至能够欺骗训练有素的观察者,那么我们就跨过了心理上的门槛,而不仅仅是技术上的门槛。

图灵测试对LLM意味着什么?
现代 LLM(如 GPT-4.5、Claude Sonnet 3.7 和 Gemini 2.5 Pro)已经在海量数据集上进行了训练;数万亿单词只是为了学习人类如何交流。这些模型并不像人类那样思考或感觉,但它们在模仿人类思考时的“声音”方面做得越来越好。
- 对于 LLM 来说,通过图灵测试并不能证明它们具有灵性,但却是功能智能的一个重要基准。
- 它证明了这些模型能够在人类社会规范内运作,驾驭模糊性,并参与语境丰富的对话。
- 这意味着 LLM 不再只是完成句子的简单工具,它们已经发展成为能够模拟与人交谈的整个体验的系统。
因此,当今天的 LLM 通过图灵测试时,它不仅仅是一个噱头或公关胜利。这表明,人工智能模型已经达到了语言和心理模仿的水平,在教学、治疗、谈判等面向人类的工作中出现人工智能模型已经变得合理,甚至不可避免。
图灵测试不再是理论。它是真实的。而我们现在正生活在它所预言的时代。
图灵测试是如何进行的?
在他们的研究中,琼斯和卑尔根重现了最初的图灵测试。阿兰-图灵的原始测试包括一名人类法官通过文本与人类和机器进行盲目交互。如果法官无法可靠地区分两者,则认为机器表现出了智能行为。

测试大致包括 5 个关键部分:
- 五分钟聊天窗口:每个测试环节的时间限制为 5 分钟,以保持互动的简短和自然。这段时间足以进行有意义的交流,同时又不会泄露太多信息。
- 果断判断:与以往许多允许开放式评估的图灵测试实验不同,本研究强迫询问者选择一个具体的答案。在每个环节中,评委必须从一轮参与者中选出一个人工智能模型和一个人类。
- 盲测:评委们不知道自己在评估哪个人工智能模型,甚至不知道自己在某些情况下是否在与机器互动。这有助于避免偏见,并确保完全根据反应来评判反应。
- 多模型测试:每次测试都有不同的 LLM 扮演不同的角色,并进行了随机化处理,以防止任何可识别的行为模式影响测试结果。
- 多样化的参与者库:评委本身来自不同的背景,包括大学生、群众工作者,甚至人工智能专家,以观察 LLM 是否能同时欺骗普通用户和技术用户。
这种实验设计创造了一个公平竞争的环境,让人感觉就像真实的网络聊天场景一样–模糊、快节奏、社交性强。通过这种结构,我们可以得出更可靠的结论,即当今的 LLM 是否能在不同人群、平台和性格中令人信服地冒充人类。
当今的图灵测试:三方互动
琼斯和伯根采用了同样的三方设置,并加入了现代元素:一名人类评委、一名人类应答者和一名人工智能模型。
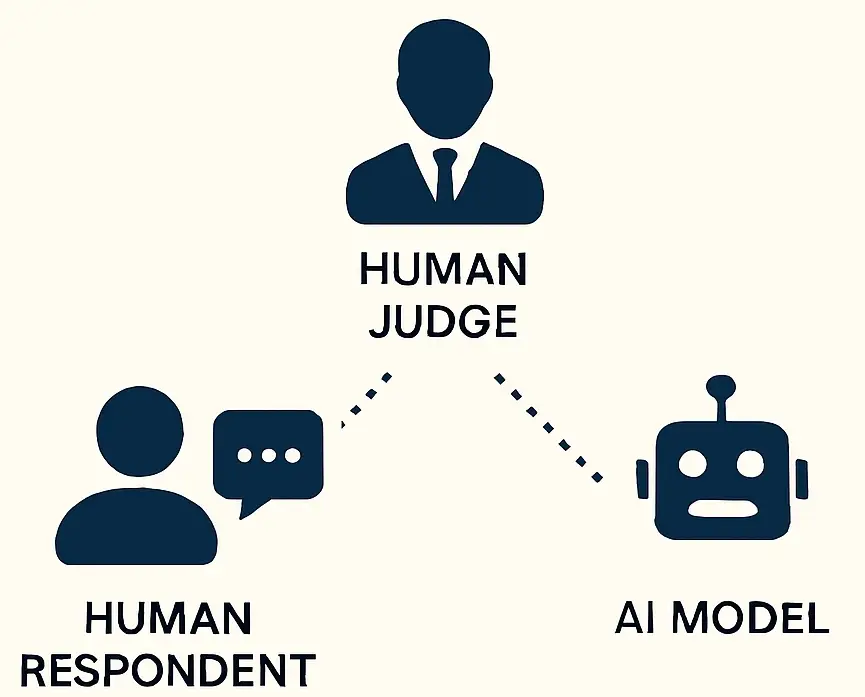
- 评委有五分钟的时间与两位参与者进行文字聊天,然后决定谁是机器。
- ELIZA 是上世纪 60 年代的一款“基于规则”的简单聊天机器人,它被用作对照组,也就是一个基本参考点。
- 它有助于检查评委是否仍能识别出明显的机器人,并设定了性能下限,显示现代 LLM 相比之下要好多少(或差多少)。
- 最后,研究人员还让 LLMs 假设互联网风格的角色,例如一个热爱备忘录、性格内向的 20 多岁年轻人。
研究人员测试了多种 LLM:
- GPT-4.5(通过 ChatGPT,使用经过调整的“角色”)
- GPT-4o(OpenAI 最新的自由层模型)
- Claude Sonnet
- Gemini 1.5 Flash
- Mistral
- ELIZA(作为基线)
这个现代化版本忠实于图灵的结构,同时更新了参与者和语境,以适应当今的人工智能对话环境。
图灵测试结果:LLM现在可以愚弄人类了
测试中最有趣的结果是 OpenAI 的 GPT-4.5 在给定一个精心设计的角色时,有 54% 到 73% 的时间都能骗过人类评委。在一些试验中,参与者更愿意相信人工智能是人类,而不是真正的人类受访者。这不仅仅是统计上的噪音,而是不同实验条件和参与者群体之间的一致模式。研究人员测试了五个领先的法律硕士和一个对照组,以下是他们的结果:
| LLM / Chatbot | 识别错误率 | 关键点 |
|---|---|---|
| GPT-4.5 | 54% – 73% | 最成功;当被赋予一个经过调整的角色时,可信度很高 |
| GPT-4o | ~50% | 与偶然性相当;既不容易被发现,也不特别令人信服 |
| Claude Sonnet | 42% | 经常被认为过于精致和结构化 |
| Gemini 1.5 Flash | 36% | 说服力相对较差;回答感觉不太自然 |
| Mistral | 26% | 经常被认为是人为的 |
| ELIZA (control) | ~0% | 一眼就能看出是机器人;作为基线 |
更有趣的是,不同用户群体的结果各不相同:
- 在线人群工作者最容易受骗,将 GPT-4.5 误认为人类的比例接近 75%。
- 大学生甚至有法律硕士经验的参与者在识别人工智能方面也没有明显优势。
这表明,即使是知情用户也很难分辨出机器和人类。
GPT-4.5如何通过图灵测试?
让 GPT-4.5 如此令人信服的并不是原始的语言能力。而是它在社交和情感参数上的表现。
研究人员发现,当为 GPT-4.5 设定一个“角色”时,它突然变得更像人类了。 一层微妙的叙事让它有了足够的瑕疵和怪癖,从而唤起了人们的共鸣。参与者表示,当模型出现小错误、表达不确定性或使用俚语或缩写等随意语言时,“感觉更自然”。
相比之下,其他过于正式或语法完美的模型则很容易被发现是机器人。
这些发现强调了一个重大转变:LLM 不需要完美到可以冒充人类,他们只需要不完美到令人信服的程度。可信度不在于事实的准确性,而在于情感和对话的共鸣。GPT-4.5 赢得比赛并不是因为它更聪明,而是因为它能准确地模拟人类的含义。
假冒人类时代的开始
如果 LLM 现在可以假装比真人更会做人,那我们就不再只是在玩游戏了。我们正在应对数字空间中人格定义方式的根本性转变。
- 客户服务:在客户支持方面,我们可能已经在与人工智能对话;但在未来,我们甚至无法发现它。
- 在线约会和社交媒体:随着人工智能档案渗入网站,我们该如何验证身份?
- 政治与错误信息:人工智能总能生成内容。但现在,它可以生成真正能引起我们共鸣的内容。在这种情况下,如果机器人可以争辩并赢得辩论,会发生什么?
- 陪伴与孤独:随着 LLM 更好地了解我们,它们能否成为我们的情感支持系统?
哲学家丹尼尔-丹尼特(Daniel Dennett)在一篇文章中对“伪造的 ”发出了警告–这些机器除了生物学事实外,其他方面看起来都像人。这篇论文表明,我们现在已经达到了这一境界。
是什么让我们成为人类?
具有讽刺意味的是,通过图灵测试的机器人并不是那些完美无缺的机器人,而是那些在各方面都不完美的机器人。那些偶尔犹豫着要不要问清楚问题,或者使用 “我不确定 ”等自然填充短语的机器人,比那些以精炼、百科全书式的精确度回答问题的机器人更有人性。
这说明了一个奇怪的事实:在我们眼中,人性是在夹缝中发现的–在不确定性、情感表达、幽默甚至尴尬中。这些都是真实和社会存在的标志。而现在,LLM 已经学会了模拟它们。
那么,当机器不仅能模仿我们的优点,还能模仿我们的弱点时,会发生什么呢?如果人工智能能如此令人信服地模仿我们的疑虑、怪癖和说话语气,那么还有什么能让我们成为独一无二的人类呢?那么,图灵测试就成了一面镜子。我们用机器做不到的事来定义人类,但这条线正变得越来越薄,非常危险。
类人AI在现实世界中的应用
随着 LLM 开始令人信服地仿真人类,各种现实世界的应用成为可能:
- 虚拟助理:人工智能代理可以在客户支持、日程安排或个人辅导等方面进行自然、引人入胜的对话,但听起来不会像机器人。
- 治疗机器人:用于心理健康支持或日常互动的人工智能伴侣,模拟同理心和社会联系。
- 人工智能辅导员和教育工作者:个性化教学助手,能像真人教师一样调整语气、节奏和反馈。
- 用于培训和模拟的角色扮演:高质量的类人人工智能代理,用于法律、医学和安全等领域的角色学习。
这些只是众多可能性中的一部分。随着人工智能与人类之间的界限逐渐模糊,我们可以预见一个生物数字世界的崛起。
小结
GPT-4.5 通过了图灵测试。但对我们来说,真正的考验才刚刚开始。在一个机器与人无法区分的世界里,我们该如何保护真实性?我们如何保护我们自己?在数字空间中,我们还能相信自己的直觉吗?
这篇论文不仅仅是一个研究里程碑。它是一个文化里程碑。它告诉我们,人工智能不只是在追赶,而是在融入。模拟与现实之间的界限越来越模糊。我们现在生活在一个机器比人更像人的世界里,至少在聊天室里的五分钟是这样。问题不再是“机器能思考吗?” 而是:我们还能分辨出谁在思考吗?
免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。












暂无评论内容