

检索增强生成(RAG)系统通过整合外部文档检索来生成语境丰富的响应,从而增强了人工智能的生成能力。随着 GPT 4.1 的发布,构建代理 RAG 系统变得更加强大、高效和易于使用。在本文中,我们将了解 GPT-4.1 的强大之处,并学习如何使用 GPT-4.1 mini 构建代理 RAG 系统。
GPT 4.1概述
GPT 4.1 在其前代产品的基础上进行了重大改进,在以下方面取得了巨大进步:
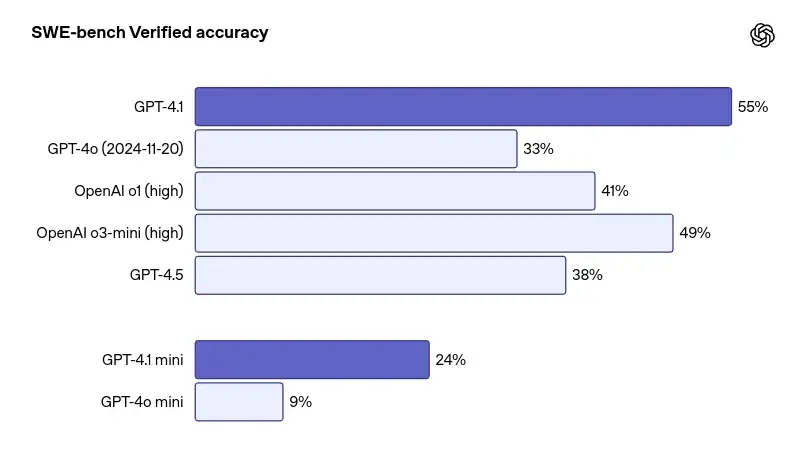
- 编码:在 SWE-bench 验证中达到 55% 的成功率,大大超过 GPT 4o。
- 指令跟踪:增强了有效处理复杂、多步骤和细微指令的能力。
- 长上下文:支持多达 100 万个标记的上下文窗口,适用于广泛的数据分析。不过,检索准确率会随着语境的延长而略有下降。
- 成本效益:与 GPT-4o 相比,GPT-4.1 的成本降低了 83%,延迟降低了 50%。
GPT 4.1有哪些新功能?
OpenAI 推出了 GPT-4.1 系列,包括三种模型: GPT-4.1、GPT-4.1 Mini 和 GPT-4.1 Nano。以下是其提供的功能:
1. 1M令牌内涵:大思维提示
最重要的功能之一是100 万个令牌上下文窗口 – 这是 OpenAI 的首创。现在,您可以一次性输入大量代码块、研究论文或整个文档集。尽管如此,虽然它的处理规模令人印象深刻,但随着输入的增加,精确度也会下降,因此它最好用于广泛的上下文理解,而不是精确的外科手术。
2. 编码升级:更智能、多语言、更准确
在编程方面,GPT-4.1 有着明显的优势:
- Python 基准测试:它在 SWE 基准测试中的得分率为 55%,超过了 GPT-4o。
- 多语言代码任务:得益于 Polyglot 基准,它能比以前更好地处理多种语言。
- 非常适合自动生成代码、调试,甚至协助全栈构建。
3. 更好的指令跟踪
GPT-4.1 现在能更好地响应多步骤指令和细微的格式规则。无论是设计工作流程还是构建人工智能代理,该模型都能更好地满足您的实际需求。
4. 速度与成本:一半的延迟,几分之一的价格
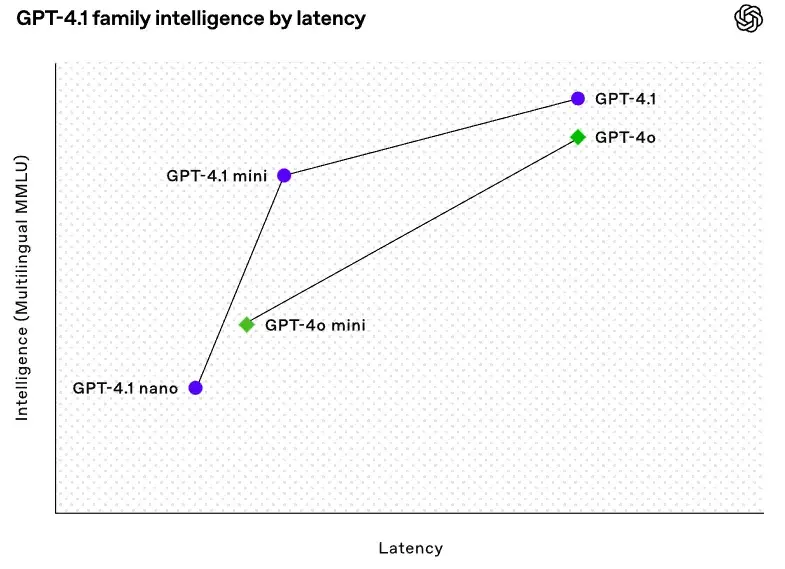
该版本针对性能和经济性进行了优化:
- 响应时间快 50
- 比 GPT-4o 便宜 83
- Nano 模型特别适合高频率、预算敏感型应用–非常适合利润空间狭小的扩展应用。
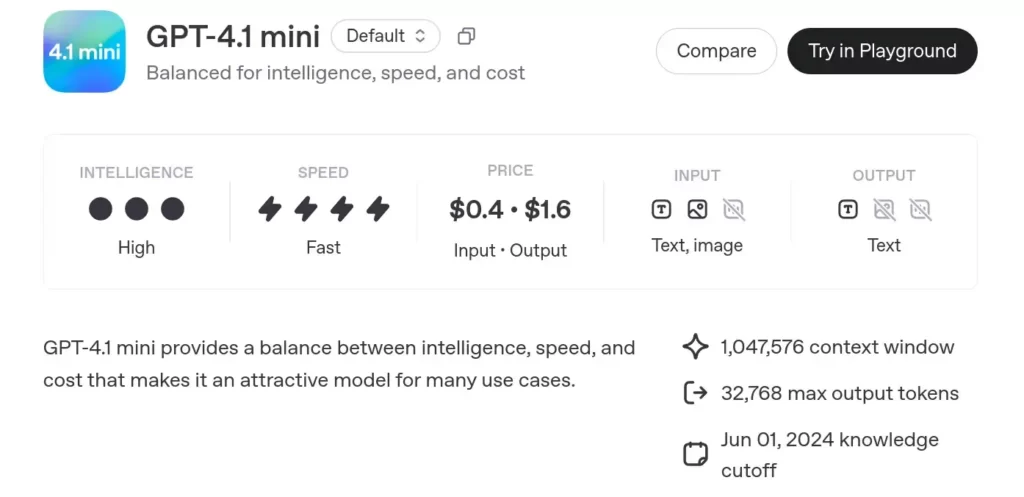
- GPT-4.1 mini 模型旨在平衡智能、速度和成本。它具有高智能和高速度的特点,适合多种使用情况。
- 定价:每输入输出 0.4 – 1.6 美元。
- 输入:文本和图像。
- 输出:文本。
- 上下文窗口:1,047,576 个 token(处理能力大)。
- 最大输出:32,768 个词组。
- 知识截止日期:2024 年 6 月 1 日。
阅读本文,了解更多有关GPT-4.1信息。
使用GPT 4.1 mini构建代理RAG
我正在使用 GPT 4.1 mini 构建一个多文档、代理式 RAG 系统。工作流程如下
- 输入两份长 PDF(ML 和 GenAI 经济学)。
- 将它们分块成重叠的片段(chunk_size=5000,chunk_overlap=300)–旨在保留上下文。
- 使用 OpenAI 的 text-embedding-3-small 模型嵌入这些块。
- 将它们存储在两个独立的 Chroma 向量存储区中,以便进行高效的基于相似性的检索。
- 将检索+LLM 提示逻辑打包成两个链(每个主题一个)。
- 将这些链作为工具提供给 LangChain Zero-Shot Agent,后者会将查询路由到正确的上下文。
- 由于采用了大块和高质量检索,像“Why is Self-Attention used?”或“How will marketing change with GenAI?”这样的查询都能得到准确且符合上下文的回答。
1. 设置和安装
!pip install langchain==0.3.23 !pip install -U langchain-openai !pip install langchain-community==0.3.11 !pip install langchain-chroma==0.1.4 !pip install pypdf
安装必要的导入程序
from langchain_community.document_loaders import PyPDFLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain_chroma import Chroma from langchain_openai import ChatOpenAI, OpenAIEmbeddings from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import RunnablePassthrough from langchain_core.output_parsers import StrOutputParser from langchain.agents import AgentType, Tool, initialize_agent
我正在锁定特定版本的 LangChain 软件包和相关依赖项,以实现兼容性–明智之举。
2. OpenAI API密钥
from getpass import getpass
OPENAI_KEY = getpass('Enter Open AI API Key: ')
import os
os.environ['OPENAI_API_KEY'] = OPENAI_KEY
3. 使用PyPDFLoader加载PDF
pdf_dir = "/content/document_pdf"
machinelearning_paper = os.path.join(pdf_dir, "Machinelearningalgorithm.pdf")
genai_paper = os.path.join(pdf_dir, "the-economic-potential-of-generative-ai-
the-next-productivity-frontier.pdf")
# Load individual PDF documents
print("Loading ml pdf...")
ml_loader = PyPDFLoader(machinelearning_paper)
ml_documents = ml_loader.load()
print("Loading genai pdf...")
genai_loader = PyPDFLoader(genai_paper)
genai_documents = genai_loader.load()
将 PDF 文件加载到 LangChain 文档对象中。每一页成为一个文档。
3. 使用RecursiveCharacterTextSplitter分块
# Split the documents
text_splitter = RecursiveCharacterTextSplitter(chunk_size=5000, chunk_overlap=300)
ml_splits = text_splitter.split_documents(ml_documents)
genai_splits = text_splitter.split_documents(genai_documents)
print(f"Created {len(ml_splits)} splits for ml PDF")
print(f"Created {len(genai_splits)} splits for genai PDF")
这是处理长上下文的核心。这个工具
- 将语块保持在 5000 个字节以下。
- 保留 300 个重叠的上下文。
递归分割器会尝试分割段落 → 句子 → 字符,尽可能保留语义结构。
Ml_splits[:3]

genai_splits[:5]

4. 使用OpenAIEmbedding进行嵌入
# details here: https://openai.com/blog/new-embedding-models-and-api-updates openai_embed_model = OpenAIEmbeddings(model='text-embedding-3-small')
我使用的是 2024 text-embedding-3-small 模型:
- 与旧模型相比,体积更小、速度更快、精度更高。
- 非常适合进行高性价比、高质量的检索。
5. 存储在Chroma矢量存储器中
# Create separate vectorstores
ml_vectorstore = Chroma.from_documents(
documents=ml_splits,
embedding=openai_embed_model,
collection_metadata={"hnsw:space": "cosine"},
collection_name="ml-knowledge"
)
genai_vectorstore = Chroma.from_documents(
documents=genai_splits,
embedding=openai_embed_model,
collection_metadata={"hnsw:space": "cosine"},
collection_name="genai-knowledge"
)
在这里,我创建了两个向量存储空间:
- 一个用于存储与 ML 相关的数据块
- 一个用于与 GenAI 相关的数据块
使用余弦相似性进行检索:
ml_retriever = ml_vectorstore.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 5,"score_threshold": 0.3})
genai_retriever = genai_vectorstore.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 5,"score_threshold": 0.3})
只返回相似度足够高的前 5 块。使答案保持紧凑。
query = "what are ML algorithms?" top3_docs = ml_retriever.invoke(query) top3_docs

6. 检索和创建提示
# Create the prompt templates
ml_prompt = ChatPromptTemplate.from_template(
"""
You are an expert in machine learning algorithms with deep technical knowledge of the field.
Answer the following question based solely on the provided context extracted from relevant machine learning research documents.
Context:
{context}
Question:
{question}
If the answer cannot be found in the context, please respond with: "I don't have enough information to answer this question based on the provided context."
"""
)
genai_prompt = ChatPromptTemplate.from_template(
"""
You are an expert in the economic impact and potential of generative AI technologies across industries and markets.
Answer the following question based only on the provided context related to the economic aspects of generative AI.
Context:
{context}
Question:
{question}
If the answer cannot be found in the context, please state "I don't have enough information to answer this question based on the provided context."
"""
)
在这里,我创建的是针对具体语境的提示:
- ML QA 系统:询问算法、训练等。
- GenAI QA 系统:关注经济影响和跨行业使用。
这些提示还可以防止出现幻觉:
“If the answer cannot be found in the context… respond with: ‘I don’t have enough information…’”
完美的可靠性。
7. LCEL链
from langchain_openai import ChatOpenAI llm = ChatOpenAI(model_name='gpt-4.1-mini-2025-04-14', temperature=0)
def format_docs(docs): return "\n\n".join(doc.page_content for doc in docs)
# Create the RAG chains using LCEL
ml_chain = (
{
"context": lambda question: format_docs(ml_retriever.get_relevant_documents(question)),
"question": RunnablePassthrough()
}
| ml_prompt
| llm
| StrOutputParser()
)
genai_chain = (
{
"context": lambda question: format_docs(genai_retriever.get_relevant_documents(question)),
"question": RunnablePassthrough()
}
| genai_prompt
| llm
| StrOutputParser()
)
这正是 LangChain Expression Language (LCEL) 的优势所在。
- 检索语块
- 将其格式化为上下文
- 注入提示符
- 发送至 gpt-4.1-mini
- 解析响应字符串
它优雅、可重用、模块化。
8. 定义代理工具
# Define the tools tools = [ Tool( name="ML Knowledge QA System", func=ml_chain.invoke, description="Useful for when you need to answer questions related to machine learning concepts, models, training techniques, evaluation metrics, algorithms and practical implementations. Covers supervised and unsupervised learning, model optimization, bias-variance tradeoff, feature engineering, and algorithm selection. Input should be a fully formed question." ), Tool( name="GenAI QA System", func=genai_chain.invoke, description="Useful for when you need to answer questions about the economic impact, market potential, and cross-industry implications of generative AI technologies. Input should be a fully formed question. Responses are based strictly on the provided context related to the economics of generative AI." ) ]
每个链都会成为 LangChain 中的一个工具。工具就像代理的即插即用功能。
9. 初始化代理
# Initialize the agent agent = initialize_agent( tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True )
我使用的是 Zero-Shot ReAct 代理,它可以解释查询,决定使用哪种工具(ML 或 GenAI),并相应地路由输入。
10. 查询时间!
result = agent.invoke("How marketing and sale could be transformed using Generative AI?")

代理:
- 选择 GenAI QA 系统
- 从 GenAI 向量存储中检索顶级上下文块
- 格式化提示
- 发送到 GPT-4.1
- 返回接地的、无幻觉的答案
result1 = agent.invoke("why Self-Attention is used?")

代理:
- 选择 ML QA 系统
- 从 ML 向量存储中检索顶级上下文块
- 格式化提示
- 发送到 GPT-4.1mini
- 返回接地的非幻听答案
result2 = agent.invoke("what are Tree-based algorithms?")

事实证明,GPT-4.1 在处理大型文档时非常有效,这要归功于其扩展的上下文窗口,可容纳多达 100 万个标记。这一改进消除了以前的模型所面临的长期限制,在以前的模型中,文档必须被大量分块成小片段,往往会失去语义的连贯性。
由于 GPT-4.1 能够处理大块文档,例如这里使用的 5000 个标记段,因此它可以对密集、信息丰富的部分进行摄取和推理,而不会丢失跨段落或跨页面的上下文链接。在涉及学术论文或行业白皮书等复杂文档的情况下,这一点尤为重要,因为对这些文档的理解往往取决于多页的连续性。该模型能准确处理这些扩展的大块内容,并提供基于上下文的响应,而不会产生幻觉,精心设计的检索提示进一步增强了这一能力。
此外,在 RAG 管道中,响应的质量在很大程度上取决于模型一次能消耗多少有用的上下文。GPT-4.1 消除了以前的上限,使检索和推理完整的概念单元而不是零散的摘录成为可能。因此,您可以对冗长的文档提出深层次、细致入微的问题,并得到精确、有理有据的回答,这使得 GPT-4.1 成为生产级文档分析和基于检索的应用的变革者。
不仅仅是Needle in a Haystack
这是一个 needle-in-a-haystack 基准测试,用于评估不同模型在检索或推理埋藏在冗长上下文(“haystack”)中的相关信息(“needle”)方面的能力。
GPT-4.1 擅长在大型文档中查找特定事实,但 OpenAI 通过 OpenAI-MRCR 基准进一步推动了这一工作,该基准测试多事实检索:
- 对于 2 个关键事实(“needles”),GPT-4.1 的表现优于 OpenAI–MRCR: GPT-4.1 比 4.0 做得更好。
- 对于 4 个或更多:像 GPT-4.5 这样的大型模型仍占优势,尤其是在较短的输入场景中。
8-needle 场景–即在较长的标记序列中嵌入 8 个相关信息,测试模型准确检索或引用这些信息的能力。
因此,虽然 GPT-4.1 可以很好地处理基本的长语境任务,但它还不能完全胜任深度的、相互关联的推理。
2 Needle
这通常是指任务的简化版本,可能是类别更少或决策点更简单。在这种情况下,“准确度”是根据模型在区分两个类别或做出两个不同决策时的表现来衡量的。
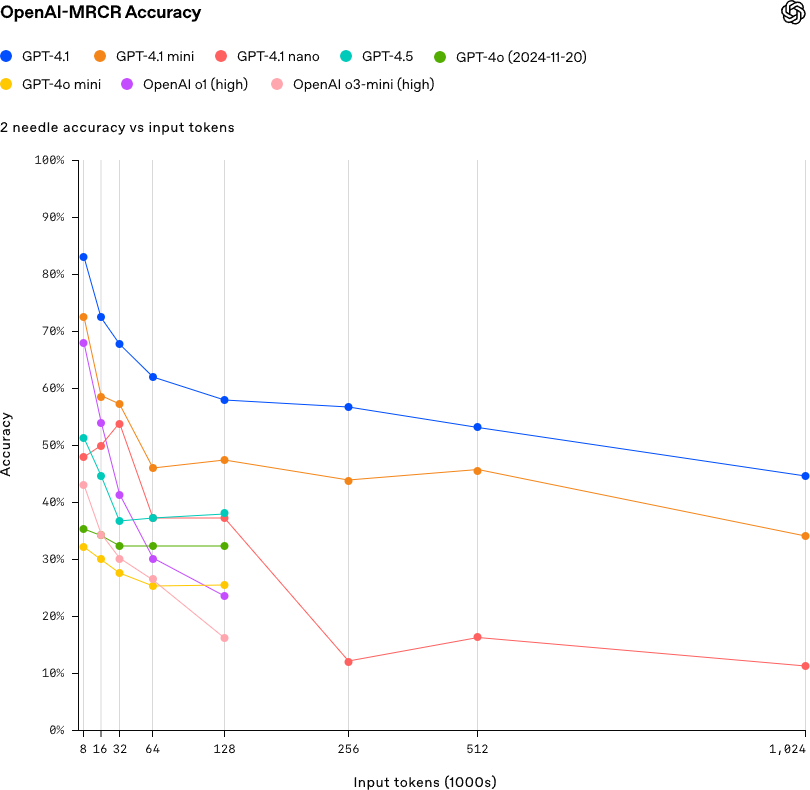
Source: OpenAI
4 Needle
这将涉及一项更复杂的任务,需要预测四个不同的类别或结果。与“2 needle”相比,这对模型来说是一项更具挑战性的任务,意味着模型必须做出更细微的区分。
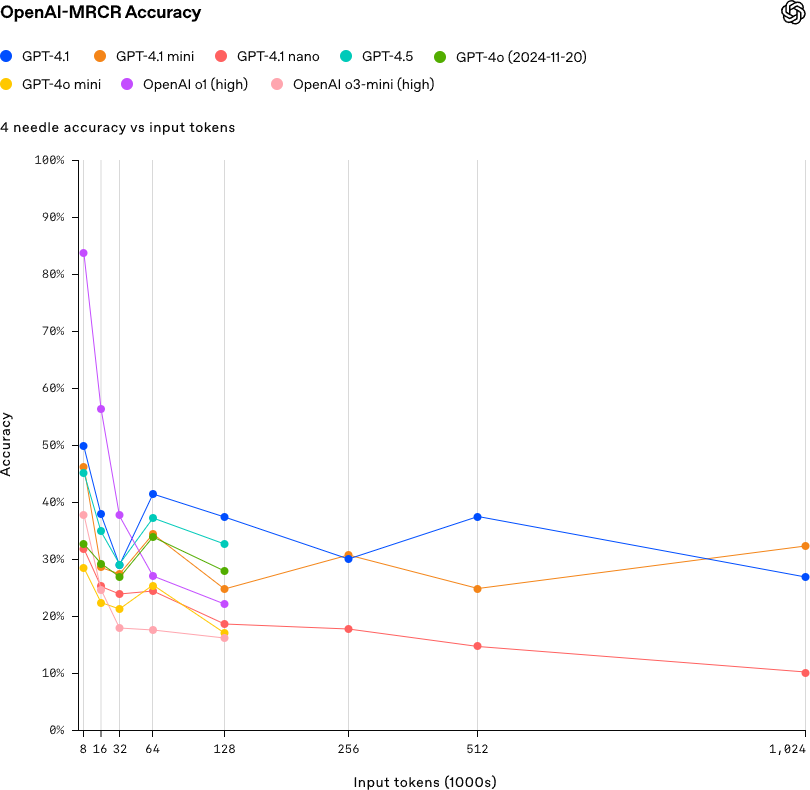
Source: OpenAI
8 Needle
这是一个更加复杂的场景,模型必须从八个不同的类别或结果中进行正确预测。needle 数越多,任务就越具有挑战性,要求模型展现出更广泛的理解力和准确性。
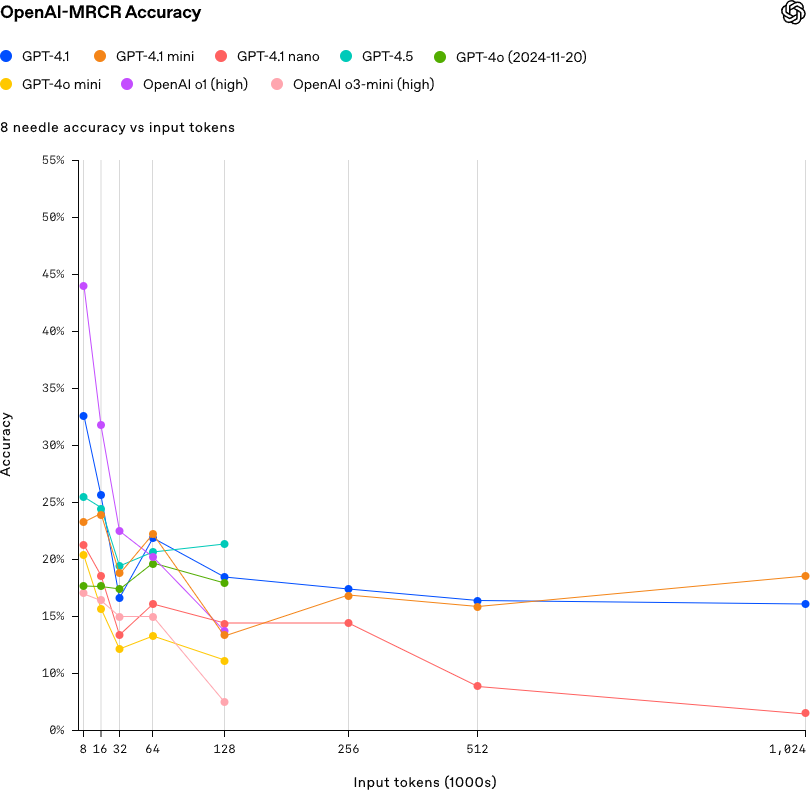
来源:OpenAI
不过,根据你的使用情况(尤其是如果你正在处理 20 万个以下的代币),DeepSeek-R1 或 Gemini 2.5 等替代品可能会给你带来更高的性价比。
但是,如果您的需求包括前沿推理或最新知识,那么请关注 GPT-4.5 或 Gemini 等竞争对手。
GPT-4.1 可能不会彻底改变游戏规则,但它是一次明智的进化,尤其是对开发者而言。OpenAI 将重点放在了实际改进上:更好的编码支持、更长的上下文处理以及更低的成本,从而使模型更容易获得。
不过,在基准透明度和知识新鲜度等方面,OpenAI 仍给竞争对手留下了跃跃欲试的空间。随着竞争的加剧,GPT-4.1 证明了 OpenAI 正在倾听–现在该谷歌、Anthropic 和其他公司行动了。
为什么分块法效果如此之好(5000 + 300 重叠)?
配置
- chunk_size = 5000
- chunk_overlap = 300
为什么这对GPT-4.1有效?
- GPT-4.1 支持 1M 标记上下文。现在,输入更长的语块终于有用了。较小的语块会遗漏跨段落的观点之间的语义粘合。
- 5000 个标记的语块可确保语义分割最小化,并捕捉到“Transformer 架构 ”或“GenAI 的经济影响”等大型概念单元。
- 300 个标记符号的重叠有助于保留跨块上下文,防止出现割裂问题。
这可能就是你没有看到遗漏或幻觉的原因–你为 LLM 提供的正是它所需的分块上下文。
好了,让我们通过一个分步指南来详细说明如何使用 GPT-4.1 构建一个代理检索-增强生成(RAG)管道,并通过对两份大型 PDF 文件(每份 50 多页)进行分块和索引来利用其 100 万个令牌上下文窗口功能,从而检索出准确的答案,且不会出现幻觉。
GPT 4.1的主要优势和注意事项
- 增强检索功能:与 GPT-4.5 等大型模型相比,在单一事实检索方面性能优越,但在复杂的多信息综合任务中效率略低。
- 成本效益 :特别是 Nano 变体,非常适合对预算敏感的高吞吐量任务。
- 对开发人员友好:非常适合编码应用、法律文件分析和冗长的上下文任务。
小结
GPT-4.1 Mini 是构建代理检索-增强生成(RAG)系统的稳健而经济的基础。GPT-4.1 Mini 支持 100 万个标记的上下文窗口,因此可以输入大量语义丰富的文档块,从而增强了模型提供基于上下文的准确响应的能力。
GPT-4.1 Mini 增强的指令跟踪能力、长语境处理能力和经济性使其成为开发复杂的生产级 RAG 应用程序的绝佳选择。它的设计有利于与大量文件进行深入、细致的交互,使其成为人工智能驱动的信息检索领域不断发展的宝贵资产。
免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。












暂无评论内容