

六个月前,LLMs.txt 作为一种开创性的文件格式问世,旨在使大型语言模型 (LLM) 可以访问网站文档。自发布以来,该标准在开发人员和内容创建者中的影响力稳步上升。如今,随着围绕模型上下文协议(MCP)的讨论愈演愈烈,LLMs.txt 作为一种久经考验、人工智能优先的文档解决方案,在人类可读内容和机器友好型数据之间架起了一座桥梁,成为人们关注的焦点。在本文中,我们将探索 LLMs.txt 的发展历程,研究其结构和优势,深入探讨技术集成(包括 Python 模块和 CLI),并将其与新兴的 MCP 标准进行比较。
LLMs.txt的兴起
背景和语境
六个月前发布的 LLMs.txt 是为了应对一个关键挑战而开发的:robots.txt 和 sitemap.xml 等传统网络文件是为搜索引擎爬虫设计的,而不是为需要简洁、经过编辑的内容的人工智能模型设计的。LLMs.txt 提供了网站文档的精简概览,使 LLMs 能够快速了解基本信息,而不会被无关的细节所困扰。
要点:
- 目的:将网站内容提炼为适合人工智能推理的格式。
- 采用: 在其短暂的生命周期内,Mintlify、Anthropic 和 Cursor 等主要平台已经集成了 LLMs.txt,凸显了其有效性。
- 当前趋势: 随着最近围绕 MCP(模型上下文协议)的讨论激增,社区正在积极比较这两种增强 LLM 能力的方法。
Twitter上的社区热议
Twitter 上的对话反映了 LLMs.txt 的快速应用和对其潜力的兴奋之情,同时有关 MCP 的讨论也在不断增加:
- Jeremy Howard (@jeremyphoward):对这一势头表示庆祝,他说:”最近几周,我提出的 llms.txt 标准确实获得了巨大的发展势头。他感谢社区–尤其是 @StripeDev 的支持,Stripe 现已在其文档网站上托管 LLMs.txt。
- Stripe Developers(@StripeDev):宣布他们已将 LLMs.txt 和 Markdown 添加到他们的文档(docs.stripe.com/llms.txt)中,使开发人员能够轻松地将 Stripe 的知识集成到任何 LLM 中。
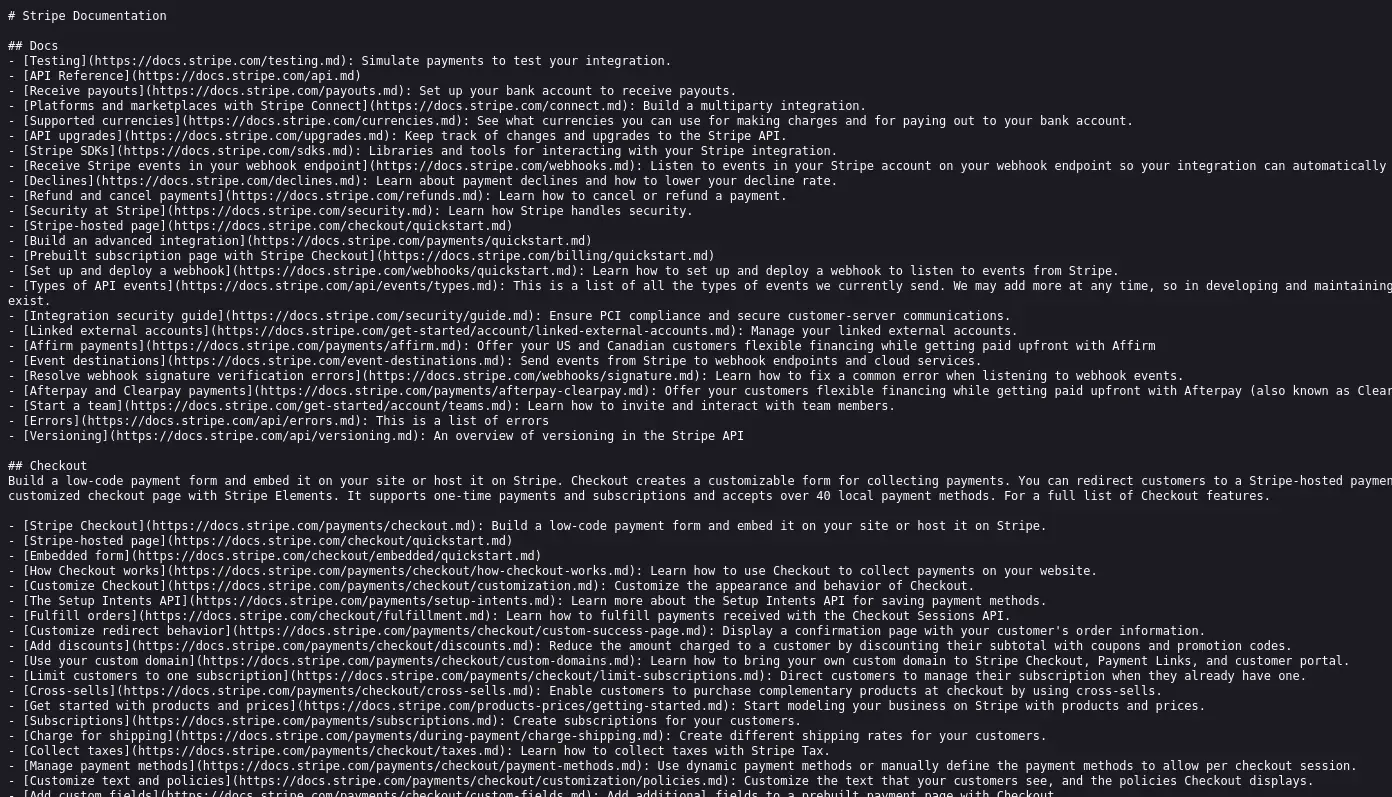
- Developer Insights:@TheSeaMouse、@xpression_app 和 @gpjt 等开发者的推文不仅称赞了 LLMs.txt,还引发了将其与 MCP 进行比较的讨论。一些用户指出,LLMs.txt 增强了内容摄取功能,而 MCP 则有望使 LLMs 更具可操作性。
什么是LLMs.txt文件?
LLMs.txt 是一种 Markdown 文件,采用结构化格式,专门设计用于使 LLM 可以访问网站文档。主要有两个版本:
/llms.txt
- 目的:提供网站文档的高层次策划概述。它可以帮助法律硕士快速掌握网站的结构并找到关键资源。
- 结构:
- 包含项目或网站名称的 H1。这是唯一必需的部分
- 包含项目简短摘要的段落引语,其中包含理解文件其余部分所需的关键信息
- 零个或多个除标题外的任何类型的标记符(如段落、列表等),包含有关项目的更多详细信息以及如何解释所提供的文件
- 零个或多个由 H2 标题分隔的标记符部分,包含可获得更多详细信息的 URL “文件列表
- 每个 “文件列表 ”都是一个标记符列表,包含一个必需的标记符超链接[名称](url),然后可选择一个:和关于文件的注释。
/llms-full.txt
- 目的:在一个地方包含完整的文档内容,在需要时提供详细的上下文。
- 用法:特别适用于技术 API 参考资料、深入指南和综合文档。
结构示例代码段:
# Project Name > Brief project summary ## Core Documentation - [Quick Start](url): A concise introduction - [API Reference](url): Detailed API documentation ## Optional - [Additional Resources](url): Supplementary information
LLMs.txt的主要优势
与传统网络标准相比,LLMs.txt 有几个明显的优势:
- 针对 LLM 处理进行了优化:它去除了导航菜单、JavaScript 和 CSS 等非必要元素,只关注 LLM 所需的关键内容。
- 高效的上下文管理:鉴于 LLM 在有限的上下文窗口中运行,LLMs.txt 的简洁格式可确保只使用最相关的信息。
- 双重可读性:Markdown 格式使 LLMs.txt 既对人友好,又易于被自动工具解析。
- 对现有标准的补充:与sitemap.xml或robots.txt不同,LLMs.txt提供了一种经过整理的、以人工智能为中心的文档视图。
如何在人工智能系统中使用LLMs.txt?
要充分利用 LLMs.txt 的优势,必须手动将其内容输入人工智能系统。以下是不同平台如何集成 LLMs.txt:
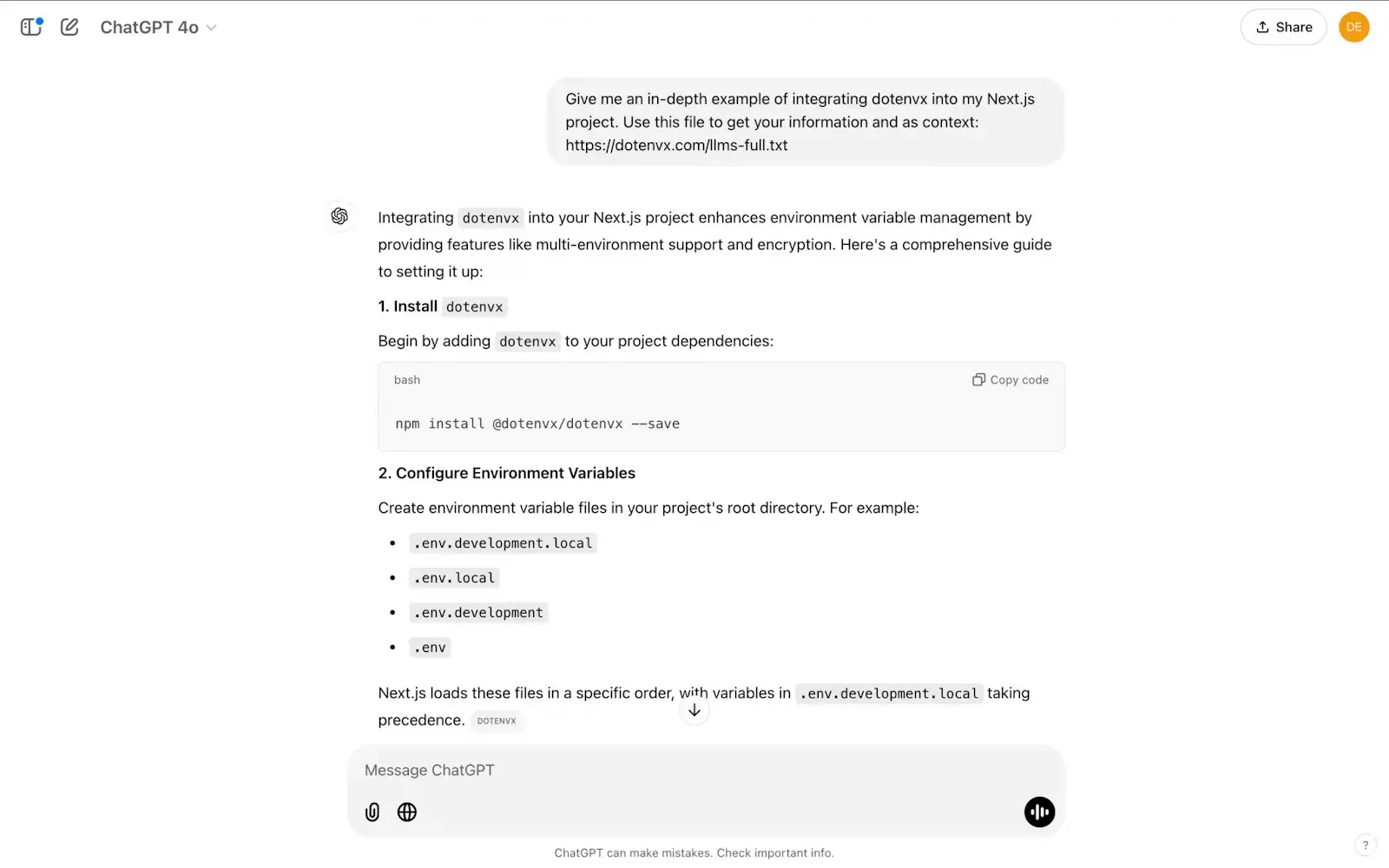
ChatGPT
- 方法:用户将 /llms-full.txt 文件的 URL 或完整内容复制到 ChatGPT 中,丰富上下文以获得更准确的回复。
- 优点:此方法可让 ChatGPT 在需要时参考详细文档。
Source – Link
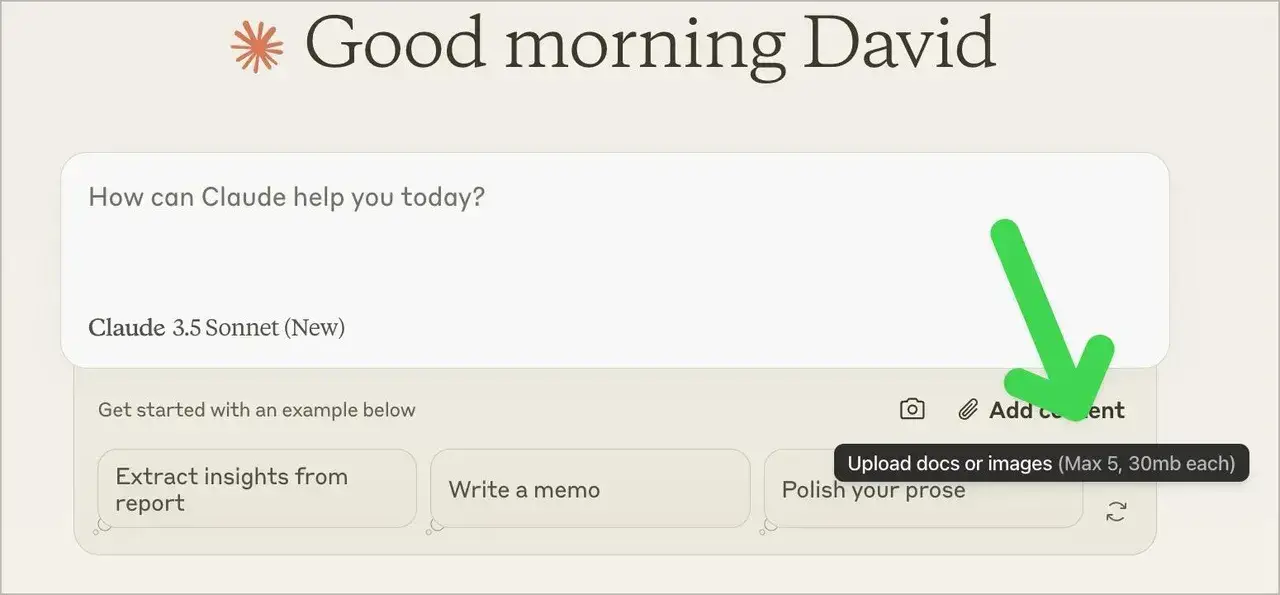
Claude
- 方法:由于 Claude 目前缺乏直接浏览功能,用户可以粘贴内容或上传文件,确保提供全面的上下文。
- 优点:这种方法使 Claude 的响应建立在可靠的最新文档基础之上。
Source – Link
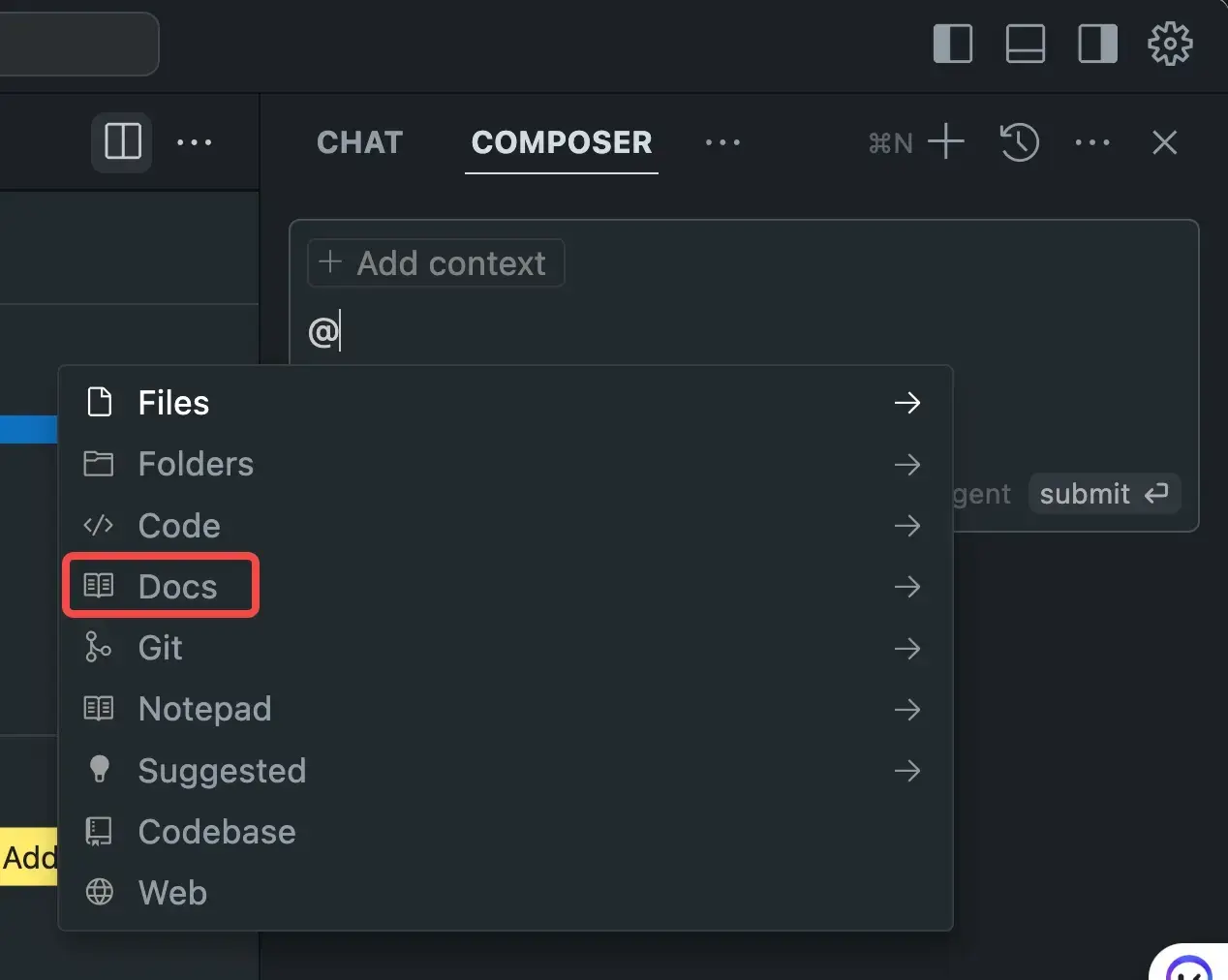
Cursor
- 方法:Cursor 的 @Docs 功能允许用户添加 LLMs.txt 链接,无缝集成外部内容。
- 优点:增强 Cursor 的上下文意识,使其成为开发人员的强大工具。
Source – Link
生成LLMs.txt文件的工具
有几种工具可以简化 LLMs.txt 文件的创建,减少人工操作:
- Mintlify:为托管文档自动生成 /llms.txt 和 /llms-full.txt 文件,确保一致性。
也可参考:https://mintlify.com/docs/quickstart
- dotenv 的 llmstxt:将网站的 sitemap.xml 转换为符合要求的 LLMs.txt 文件,与现有工作流程无缝整合。
- Firecrawl 的 llmstxt:利用网络抓取技术将网站内容编译成 LLMs.txt 文件,最大限度地减少人工干预。
实际应用和多功能性
LLMs.txt 文件的多功能性从 FastHTML 等现实世界的项目中可见一斑,这些项目遵循了这两项关于人工智能友好型文档的建议:
- FastHTML文档:FastHTML项目不仅使用LLMs.txt文件提供其文档的精选概览,还提供了一个普通的HTML文档页面,其URL与.md扩展名相同。这种双重方法确保人类读者和 LLM 都能以最合适的格式访问内容。
- 自动扩展:FastHTML 项目选择使用基于 XML 的结构将其 LLMs.txt 文件自动扩展为两个标记符文件。这两个文件是
- llms-ctx.txt: 包含上下文,但不包含可选的 URL。
- llms-ctx-full.txt: 包含可选 URL,以提供更全面的上下文。
- 这些文件通过 llms_txt2ctx 命令行应用程序生成,FastHTML 文档提供了详细的使用指南。
- 在各种应用中的通用性:除了技术文档,LLMs.txt 文件在各种情况下都很有用–从帮助开发人员浏览软件文档,到帮助企业概述其结构、为利益相关者分解复杂的立法,甚至提供个人网站内容(如简历)。同样,使用 nbdev 的 Answer.AI 和 fast.ai 项目也使用此功能重新生成文档–fastcore 的文档模块的 markdown 版本就是例证。
LLMs.txt的Python模块和 CLI
对于希望将 LLMs.txt 集成到其工作流程中的开发人员,我们提供了专门的 Python 模块和 CLI,用于解析 LLMs.txt 文件并创建适合 Claude 等系统的 XML 上下文文档。该工具不仅可以轻松地将文档转换为 XML,还提供了命令行界面和 Python API。
安装
pip install llms-txt
如何使用?
CLI
安装后, llms_txt2ctx 可在终端中使用。
要获取 CLI 的帮助,请:
llms_txt2ctx -h
将 llms.txt 文件转换为 XML 上下文并保存为 llms.md:
llms_txt2ctx llms.txt > llms.md
通过 -optional True 添加输入文件的“可选”部分。
Python模块
from llms_txt import *
samp = Path('llms-sample.txt').read_text()
使用 parse_llms_file 创建一个包含 llms.txt 文件各部分的数据结构(如果需要,也可以添加 optional=True):
parsed = parse_llms_file(samp) list(parsed) ['title', 'summary', 'info', 'sections'] parsed.title,parsed.summary
实现与测试
为了说明解析 llms.txt 文件有多简单,下面是一个完整的解析器,只用了不到 20 行代码,没有任何依赖关系:
from pathlib import Path import re,itertools def chunked(it, chunk_sz): it = iter(it) return iter(lambda: list(itertools.islice(it, chunk_sz)), []) def parse_llms_txt(txt): "Parse llms.txt file contents in `txt` to a `dict`" def _p(links): link_pat = '-\s*\[(?P[^\]]+)\]\((?P[^\)]+)\)(?::\s*(?P.*))?' return [re.search(link_pat, l).groupdict() for l in re.split(r'\n+', links.strip()) if l.strip()] start,*rest = re.split(fr'^##\s*(.*?$)', txt, flags=re.MULTILINE) sects = {k: _p(v) for k,v in dict(chunked(rest, 2)).items()} pat = '^#\s*(?P<title>.+?$)\n+(?:^>\s*(?P<summary>.+?$)$)?\n+(?P.*)' d = re.search(pat, start.strip(), (re.MULTILINE|re.DOTALL)).groupdict() d['sections'] = sects return d</pre> <p>我们在 tests/test-parse.py 中提供了一个测试套件,并确认该实现通过了所有测试。</p> <h2>Python 源代码概述</h2> <p>llms_txt Python 模块提供了创建和使用 llms.txt 文件所需的源代码和助手。下面是其功能的简要概述:</p> <ul> <li><strong>文件规范:</strong>该模块遵循 llms.txt 规范:一个 H1 标题、一个小标题摘要、可选内容部分和包含文件列表的 H2 分隔部分。</li> <li><strong>解析助手:</strong>例如,parse_link(txt) 可从标记符链接中提取标题、URL 和可选描述。</li> <li><strong>XML 转换:</strong>create_ctx 和 mk_ctx 等函数可将解析后的数据转换为 XML 上下文文件,这对 Claude 等系统尤其有用。</li> <li><strong>命令行界面:</strong>CLI 命令 llms_txt2ctx 使用这些助手处理 llms.txt 文件并输出 XML 上下文文件。该工具简化了将 llms.txt 整合到各种工作流程中的过程。</li> <li><strong>简洁的实现:</strong>该模块甚至包括一个不到 20 行代码的解析器,利用 regex 和 chunked 等辅助函数进行高效处理。</li> </ul> <p>更多详情,请参阅此链接 – https://llmstxt.org/core.html</p> <h2>比较LLMs.txt和MCP(模型上下文协议)</h2> <p>虽然 LLMs.txt 和新兴的 Model Context Protocol (MCP) 都旨在增强 LLM 功能,但它们应对的是人工智能生态系统中的不同挑战。下面是深入探讨两种方法的增强比较:</p> <h3>LLMs.txt</h3> <ul> <li><strong>目标:</strong>通过将网站文档提炼为结构化的 Markdown 格式,专注于为 LLM 提供简洁、精心策划的内容。</li> <li><strong>实现:</strong>由网站所有者维护的静态文件,是技术文档、API 参考资料和综合指南的理想选择。</li> <li><strong>优点:</strong> <ul> <li>简化内容摄取。</li> <li>易于实施和更新。</li> <li>通过过滤掉不必要的元素来提高提示质量。</li> </ul> </li> </ul> <h3>MCP(模型上下文协议)</h3> <h4>什么是MCP?</h4> <p>MCP 是一种开放标准,可在数据和人工智能工具之间建立安全的双向连接。可以把它想象成人工智能应用的 USB-C 端口–一个让不同工具和数据源相互“对话”的通用连接器。</p> <h4>MCP为何重要?</h4> <p>随着人工智能助手成为我们日常工作流程中不可或缺的一部分(如 Replit、GitHub Copilot 或 Cursor IDE),确保它们能够访问所需的所有上下文至关重要。如今,集成新的数据源往往需要定制代码,既杂乱又耗时。MCP 通过以下方式简化了这一过程:</p> <ul> <li><strong>提供预建集成:</strong>不断增加的即用连接器库。</li> <li><strong>提供灵活性:</strong>实现不同人工智能提供商之间的无缝切换。</li> <li><strong>增强安全性:</strong>确保您的数据在基础设施内的安全。</li> </ul> <p style="text-align: center"><img decoding="async" src="https://www.wpwpp.com/wp-content/themes/zibll/img/thumbnail-lg.svg" data-src="https://www.wpwpp.com/wp-content/uploads/2025/04/image-64.webp" ></p> <p style="text-align: center">Source – Link</p> <h3>MCP如何工作?</h3> <p>MCP 采用客户服务器架构:</p> <ul> <li><strong>MCP 主机:</strong>希望访问数据的程序(如 Claude Desktop 或流行的集成开发环境)。</li> <li><strong>MCP 客户端:</strong>与 MCP 服务器保持 1:1 连接的组件。</li> <li><strong>MCP 服务器:</strong>公开特定数据源或工具的轻量级适配器。</li> <li><strong>连接生命周期:</strong> <ol> <li><strong>初始化:</strong>交换协议版本和功能。</li> <li><strong>信息交换:</strong>支持请求-响应模式和通知。</li> <li><strong>终止:</strong>彻底关闭、断开连接或处理错误。</li> </ol> </li> </ul> <h3>现实世界的影响和早期采用</h3> <p>想象一下,如果您的人工智能工具可以无缝访问本地文件、数据库或远程服务,而无需为每个连接编写自定义代码。MCP 承诺正是如此–简化人工智能工具与各种数据源的集成方式。早期采用者已经在各种环境中尝试使用 MCP,从而简化了工作流程,减少了开发开销。</p> <h3>共同动机和关键差异</h3> <p><strong>共同目标:</strong>LLMs.txt 和 MCP 的目标都是增强 LLMs 的能力,但它们是以互补的方式实现这一目标的。LLMs.txt 通过提供经过整理的精简网站文档视图来改进内容摄取,而 MCP 则通过使 LLM 能够执行现实世界中的任务来扩展他们的功能。从本质上讲,LLMs.txt 帮助法律硕士更好地 “阅读”,而 MCP 则帮助他们有效地 “行动”。</p> <h4>解决方案的性质</h4> <ul> <li><strong>LLMs.txt:</strong> <ul> <li><em>静态、经过编辑的内容标准:</em> LLMs.txt 设计为静态文件,严格遵守基于 Markdown 的结构。它包括一个 H1 标题、一个块状引文摘要和以 H2 分隔的部分,其中包含经过编辑的链接列表。</li> <li><em>技术优势:</em> <ul> <li><strong>令牌效率:</strong>通过过滤掉非必要的细节(如导航菜单、JavaScript 和 CSS),LLMs.txt 将复杂的网页内容压缩成简洁的格式,适合 LLMs 的有限上下文窗口。</li> <li><strong>简单:</strong>它的格式易于使用标准文本处理工具(如 regex 和 Markdown 解析器)生成和解析,因此可供广大开发人员使用。</li> </ul> </li> <li><em>增强能力:</em> <ul> <li>提高提供给 LLM 的上下文的质量,从而实现更准确的推理和更好的响应生成。</li> <li>由于其结构是可预测和机器可读的,因此便于测试和迭代改进。</li> </ul> </li> </ul> </li> <li><strong>MCP(模型上下文协议):</strong> <ul> <li><em>动态、行动启用协议:</em>MCP 是一个强大的开放标准,可在 LLM 与外部数据源或服务之间创建安全的双向通信。</li> <li><em>技术优势:</em> <ul> <li><strong>标准化 API 接口:</strong>MCP 就像一个通用连接器(类似于 USB-C 端口),允许 LLM 与各种数据源(本地文件、数据库、远程 API 等)无缝对接,无需为每次集成定制代码。</li> <li><strong>实时交互:</strong>通过客户端-服务器架构,MCP 支持动态请求-响应周期和通知,使 LLM 能够获取实时数据并执行任务(如发送电子邮件、更新电子表格或触发工作流)。</li> <li><strong>复杂性处理:</strong>MCP 必须应对身份验证、错误处理和异步通信等挑战,因此工程密集度更高,但在扩展 LLM 功能方面也更加灵活。</li> </ul> </li> <li><em>增强能力:</em> <ul> <li>将 LLM 从被动的文本生成器转变为主动的任务执行助手。</li> <li>便于将 LLM 无缝集成到业务流程和开发工作流程中,通过自动化提高生产力。</li> </ul> </li> </ul> </li> </ul> <h4>易于实施</h4> <ul> <li><strong>LLMs.txt:</strong> <ul> <li>实施起来相对简单。它的创建和解析依赖于轻量级文本处理技术,只需最小的工程开销。</li> <li>可手动或通过简单的自动化工具进行维护。</li> </ul> </li> <li><strong>MCP:</strong> <ul> <li>需要强大的工程设计。实施 MCP 需要设计安全的应用程序接口、管理客户-服务器架构,并不断维护与不断发展的外部服务标准的兼容性。</li> <li>涉及开发预置连接器和处理复杂的实时数据交换。</li> </ul> </li> </ul> <p><strong>共同作用:</strong>这些创新是增强 LLM 能力的互补战略。LLMs.txt 可确保 LLM 拥有高质量、浓缩的基本内容快照,从而大大提高理解能力和响应质量。与此同时,MCP 允许 LLM 在静态内容和动态操作之间架起桥梁,从而提升 LLM 的能力,最终将 LLM 从单纯的内容分析仪转变为可执行任务的交互式系统。</p> <h2>结论</h2> <p>六个月前发布的 LLMs.txt 已经在人工智能文档领域占据了重要的一席之地。LLMs.txt 为 LLMs 提供了一种经过精心策划的精简方法来摄取和理解复杂的网站文档,从而大大提高了人工智能响应的准确性和可靠性。它的简单性和令牌效率使其成为开发人员和内容创建者的宝贵工具。</p> <p>与此同时,模型上下文协议(MCP)的出现标志着 LLM 功能的进一步发展。MCP 的动态标准化方法使 LLM 能够无缝访问外部数据源和服务并与之交互,将它们从被动的阅读器转变为主动的任务执行助手。LLMs.txt 和 MCP 共同体现了强大的协同效应:LLMs.txt 确保人工智能模型获得最佳上下文,而 MCP 则为它们提供了根据上下文采取行动的手段。</p> <p>展望未来,人工智能驱动的文档和自动化的前景似乎越来越光明。随着最佳实践和工具的不断发展,开发人员可以期待集成度更高、更安全、更高效的系统,这些系统不仅能增强 LLM 的能力,还能重新定义我们与数字内容的交互方式。无论您是致力于创新的开发人员,还是旨在优化工作流程的企业主,抑或是渴望探索技术前沿的人工智能爱好者,现在都是深入研究这些标准并释放人工智能文档全部潜力的时候了。</p> </div> <div class="em09 muted-3-color"><div><span>©</span> 版权声明</div><div class="posts-copyright"><!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>免责声明 - wpwpp.com 免责声明
- 本站文章均为原创,除非另有说明,否则本站内容依据 CC BY-NC-SA 4.0 许可证进行授权,转载请附上出处链接及本声明,谢谢。
- 本站提供的资源(插件或主题)均为网上搜集,如有涉及或侵害到您的版权,请立即通过邮箱 admin@wpwpp.com 通知我们。
- 本站所有下载文件,仅用作学习研究使用,下载后请在 24小时内 删除。请支持正版,切勿用作商业用途。
- 因代码可变性,本站不保证兼容所有浏览器、不保证兼容所有版本的 WordPress,不保证兼容您安装的其他插件。
- 本站保证所提供资源(插件或主题)的完整性,但不含授权许可、帮助文档、XML文件、PSD、后续升级等。
- 使用该资源(插件或主题)需要用户有一定代码基础知识!本站只提供汉化及安装教程,仅供参考。由本站提供的资源对您的网站或计算机造成严重后果的,本站概不负责。
- 有时可能会遇到部分字段无法汉化,同时请保留作者汉化宣传信息,谢谢!
- 本站资源售价只是赞助和汉化辛苦费,收取费用仅维持本站的日常运营所需。
- 如果您喜欢本站资源,开通会员享受更多优惠折扣,谢谢支持!
- 如果网盘地址失效,请在相应资源页面下留言,我们会尽快修复下载地址。
- 本站网址:wpwpp.com,联系邮箱:admin@wpwpp.com。